
One of the more difficult things to learn in KQL (apart from joining tables together) is how to deal with multi-value sets of data. If you work in particular types of data, such as Azure AD sign in data, or Security Alert data, you will see lots of these data sets too. There is no avoiding them. What do I mean by multi-value? We are talking about a set of data that is a JSON array and has multiple objects within it. Those objects may even have further nested arrays. It can quickly get out of hand and become difficult to make sense of.

Let’s look at an example. Azure AD Conditional Access policies. Each time you sign into Azure AD, it will evaluate all the policies in your tenant. Some it will apply, and maybe enforce MFA, some may not be applied because you aren’t in scope of the policy. Others may be in report only mode or be disabled entirely. At the end of your sign in, the logs will show the outcome of all your policies. The data looks a bit like this:

We get this massive JSON array, then within that we get an object for each policy, showing the relevant outcome. In this example we have 6 policies, starting from 0. Within each object, you may have further arrays, such as the ‘enforcedGrantControls’. This is because a policy may have multiple controls, such as requiring MFA and a compliant device.

You can have a look in your own tenant simply enough by looking at just the Conditional Access data.
SigninLogs
| take 10
| project ConditionalAccessPoliciesWhere multi-value data can get tricky is that the order of the data, or the location of particular data can change. If we again take our Conditional Access data, it can change order depending on the outcome of the sign in. Any policies that are successful, such as a user completing MFA, or a policy that failed, by a user failing MFA, will be moved to the top of the JSON array.
So, when I successfully complete MFA on an Azure management web site, the ‘CA006: Require multi-factor authentication for Azure management’ (as seen above) policy will go to the top of the array. When I sign into something other than Azure, that policy will be ‘notApplied’ and be in a different location within the array.
Why is this a problem? KQL is very specific, so if we want to run an alert when someone fails ‘CA006: Require multi-factor authentication for Azure management’ we need to make sure our query is accurate. If we right-click on our policy and do the built-in ‘Include’ functionality in Sentinel:

It gives us the following query:
SigninLogs
| project ConditionalAccessPolicies
| where ConditionalAccessPolicies[3].displayName == "CA006: Require multi-factor authentication for Azure management"We can see in this query that we are looking for when ConditionalAccessPolicies[3].displayName == “CA006: Require multi-factor authentication for Azure management”. The [3] indicated shows that we are looking for the 4th object in our array (we start counting at 0). So, what happens when someone fails this policy? It will move up the JSON array into position 0, and our query won’t catch it.
So how do we deal with these kinds of data? I present to you, mv-expand and mv-apply.
mv-expand
mv-expand, or multi-value expand, at its most basic, takes a dynamic array of data and expands it out to multiple rows. When we use mv-expand, KQL expands out the dynamic data, and simply duplicates any non-dynamic data. Leaving us with multiple rows to use in our queries.
mv-expand is essentially the opposite of summarize operators such as make_list and make_set. With those we are creating arrays, mv-expand we are reversing that, and expanding arrays.
As an example, let’s find the sign-in data for my account. In the last 24 hours, I have had 3 sign-ins into this tenant.

Within each of those, as above, we have a heap of policies that are evaluated.

I have cut the screenshot off for the sake of brevity, but I can tell you that in this tenant 22 policies are evaluated on each sign in. Now to see what mv-expand does, we add that to our query.
SigninLogs
| project TimeGenerated, UserPrincipalName, Location, ConditionalAccessPolicies
| mv-expand ConditionalAccessPoliciesIf we run our query, we will see each policy will be expanded out to a new record. The timestamp, location and username are simply duplicated, because they are not dynamic data. In my tenant, I get 22 records per sign in, one for each policy.
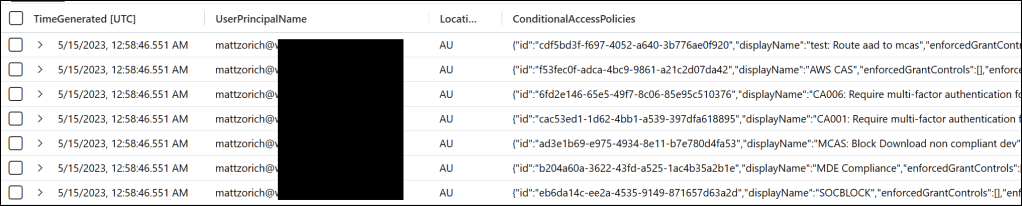
If we look at a particular record, we can see the Conditional Access policy is no longer positional within a larger array, because we have a separate record for each entry.
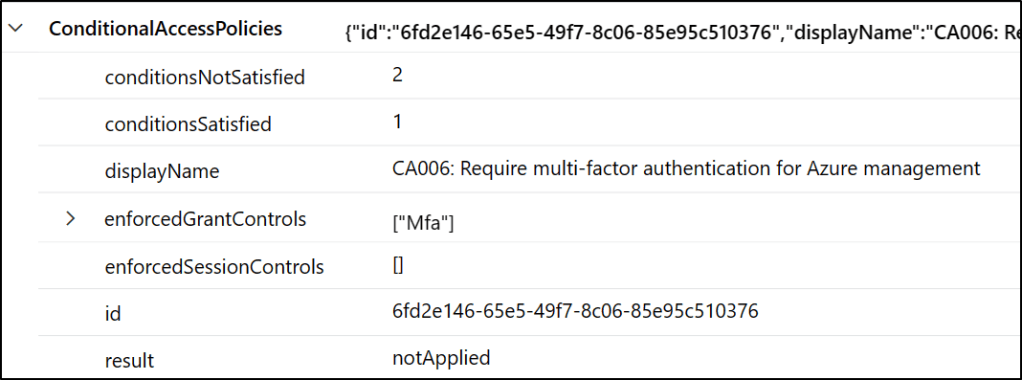
Now, if we are interested in our same “CA006: Require multi-factor authentication for Azure management” policy, and any events for that. We again do our right-click ‘Include’ Sentinel magic.

We will get the following query
SigninLogs
| project TimeGenerated,UserPrincipalName, Location, ConditionalAccessPolicies
| mv-expand ConditionalAccessPolicies
| where ConditionalAccessPolicies.displayName == "CA006: Require multi-factor authentication for Azure management"This time our query no longer has the positional [3] we saw previously. We have expanded our data out and made it more consistent to query on. So, this time if we run our query, we will get a hit for every time the policy name is “CA006: Require multi-factor authentication for Azure management”, regardless of where in the JSON array it is. When we run that query, we get 3 results, as we would expect. One policy hit per sign in for the day.

Once you have expanded your data out, you can then create your hunting rules knowing the data is in a consistent location. So, returning to our original use case, if we want to find out where this particular policy is failing, this is our final query:
SigninLogs
| project TimeGenerated,UserPrincipalName, Location, ConditionalAccessPolicies
| mv-expand ConditionalAccessPolicies
| extend CAResult = tostring(ConditionalAccessPolicies.result)
| extend CADisplayName = tostring(ConditionalAccessPolicies.displayName)
| where CADisplayName == "CA006: Require multi-factor authentication for Azure management"
| where CAResult == "failure"So, we have used mv-expand to ensure our data is consistent, and then looked for failures on that particular policy.

And we can see, we have hits on that new hunting query.
mv-apply
mv-apply, or multi-value apply adds to mv-expand, by allowing you to create a sub-query, and then returning the results. So, what does that actually mean? mv-apply actually runs mv-expand initially but gives us more freedom to create an additional query before returning the results. mv-expand is kind of like a hammer, we will just expand everything out and deal with it later. mv-apply gives us the ability to filter and query the expanded data, before returning it.
The syntax for mv-apply can be a little tricky to start with. To make things easy, let’s use our same data once again. Say we are interested in the Conditional Access stats for any policy that references ‘Azure’ or ‘legacy’ (for legacy auth), or any policy that has failures associated with it.
We could do an mv-expand as seen earlier, or we can use mv-apply to create that query during the expand.
SigninLogs
| project TimeGenerated,UserPrincipalName, Location, ConditionalAccessPolicies
| mv-apply ConditionalAccessPolicies on
(
where ConditionalAccessPolicies.displayName has_any ("Azure","legacy") or ConditionalAccessPolicies.result == "failure"
| extend CADisplayName=tostring(ConditionalAccessPolicies.displayName)
| extend CAResult=tostring(ConditionalAccessPolicies.result)
)
| summarize count() by CADisplayName, CAResultSo, for mv-apply, we start with mv-apply on. After that we create our subquery. Our sub-query is defined in the ( and ) seen after mv-apply. Interestingly, and quite unusual for KQL, is that the first line of the sub query does not require a | to precede it. Subsequent lines within the subquery do require it, as usual with KQL.
In this query we are looking for any policy names with ‘Azure’ or ‘legacy’ in them, or where the result is a failure. Then our query says if there is match on any of those conditions, then extend out our display name and result to new columns. Then finally we can summarize our data to provide some stats.

We are returned only the stats for matches of our sub-query. Either where the policy name has ‘Azure’ or ‘legacy’ or where the result is a failure.
Think of mv-apply as the equivalent of a loop statement through your expanded data. As it runs through each loop or row of data, it applies your query to each row.
It is important to remember order of operations when using mv-apply, if you summarize data inside the mv-apply ‘loop’ it will look much different to when you do it after the mv-apply has finished. Because it is within the ‘loop’, it will summarize it for every row of expanded data.
mv-apply is particularly valuable when dealing with JSON arrays that have additional arrays within them. You can mv-apply multiple times to get to the data you are interested in. On each loop, you can filter your query. Using a different data set, we can see an example of this. In the Azure AD audit logs, there is very often a quite generic event called ‘Update user’. This can be triggered on numerous things: name or licensing changes, email address updates or changes to MFA details etc.
In a lot of Azure AD audit logs, the interesting data is held in the ‘targetResources’ field. However, beneath that is a field called ‘modifiedProperties’. The modifiedProperties field has the detail of what actually changed on the user.
AuditLogs
| where TimeGenerated > ago(90d)
| where TargetResources has "PhoneNumber"
| where OperationName has "Update user"
| where TargetResources has "StrongAuthenticationMethod"
| extend InitiatedBy = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend UserPrincipalName = tostring(TargetResources[0].userPrincipalName)
| extend targetResources=parse_json(TargetResources)
| mv-apply tr = targetResources on (
extend targetResource = tr.displayName
| mv-apply mp = tr.modifiedProperties on (
where mp.displayName == "StrongAuthenticationUserDetails"
| extend NewValue = tostring(mp.newValue)
))
| project TimeGenerated, NewValue, UserPrincipalName,InitiatedBy
| mv-expand todynamic(NewValue)
| mv-expand NewValue.[0]
| extend AlternativePhoneNumber = tostring(NewValue.AlternativePhoneNumber)
| extend Email = tostring(NewValue.Email)
| extend PhoneNumber = tostring(NewValue.PhoneNumber)
| extend VoiceOnlyPhoneNumber = tostring(NewValue.VoiceOnlyPhoneNumber)
| project TimeGenerated, UserPrincipalName, InitiatedBy,PhoneNumber, AlternativePhoneNumber, VoiceOnlyPhoneNumber, Email
| where isnotempty(PhoneNumber)
| summarize ['Count of Users']=dcount(UserPrincipalName), ['List of Users']=make_set(UserPrincipalName) by PhoneNumber
| sort by ['Count of Users'] desc In this example, we use mv-apply to find where the displayName of the modifiedProperties is ‘StrongAuthenticationUserDetails’. This indicates a change to MFA details, perhaps a new phone number has been registered. This particular query then looks for when it is indeed a phone number change. It then summarizes the number of users registered to the same phone number. This query is looking for Threat Actors that are registering the same MFA number to multiple users.
By using a ‘double’ mv-apply, we filter out all the ‘Update user’ events that we aren’t interested in, and focus down on the ‘StrongAuthenticationUserDetails’ events. We don’t get updates to say licensing events, that would be captured more broadly in an ‘Update user’ event.
Summary
mv-apply and mv-expand are just a couple of the ways to extract dynamic data in KQL. There are additional operators, such as bag_unpack, and even operators for other data types, such as parse_xml. I find myself coming constantly back to mv-expand and mv-apply, mostly because of the ubiquitousness of JSON in security products.

One thought on “Have a JSON headache in KQL? Try mv-expand or mv-apply”
1 Pingback