One of the more difficult things to learn in KQL (apart from joining tables together) is how to deal with multi-value sets of data. If you work in particular types of data, such as Azure AD sign in data, or Security Alert data, you will see lots of these data sets too. There is no avoiding them. What do I mean by multi-value? We are talking about a set of data that is a JSON array and has multiple objects within it. Those objects may even have further nested arrays. It can quickly get out of hand and become difficult to make sense of.
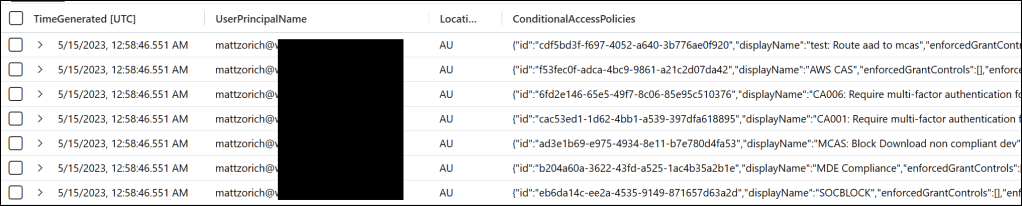
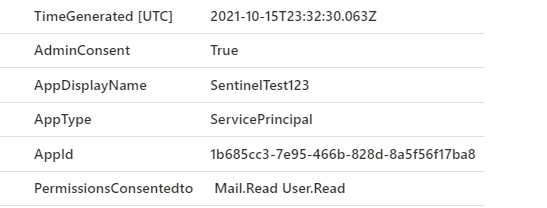
Let’s look at an example. Azure AD Conditional Access policies. Each time you sign into Azure AD, it will evaluate all the policies in your tenant. Some it will apply, and maybe enforce MFA, some may not be applied because you aren’t in scope of the policy. Others may be in report only mode or be disabled entirely. At the end of your sign in, the logs will show the outcome of all your policies. The data looks a bit like this:
We get this massive JSON array, then within that we get an object for each policy, showing the relevant outcome. In this example we have 6 policies, starting from 0. Within each object, you may have further arrays, such as the ‘enforcedGrantControls’. This is because a policy may have multiple controls, such as requiring MFA and a compliant device.
You can have a look in your own tenant simply enough by looking at just the Conditional Access data.
SigninLogs
| take 10
| project ConditionalAccessPolicies
Where multi-value data can get tricky is that the order of the data, or the location of particular data can change. If we again take our Conditional Access data, it can change order depending on the outcome of the sign in. Any policies that are successful, such as a user completing MFA, or a policy that failed, by a user failing MFA, will be moved to the top of the JSON array.
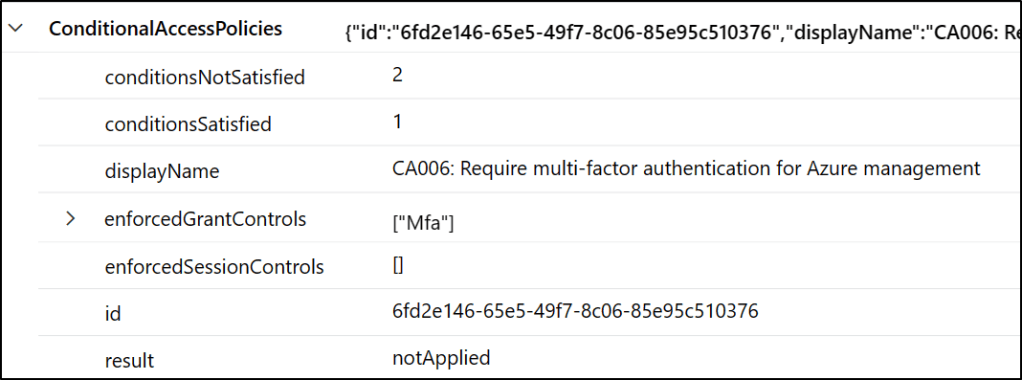
So, when I successfully complete MFA on an Azure management web site, the ‘CA006: Require multi-factor authentication for Azure management’ (as seen above) policy will go to the top of the array. When I sign into something other than Azure, that policy will be ‘notApplied’ and be in a different location within the array.
Why is this a problem? KQL is very specific, so if we want to run an alert when someone fails ‘CA006: Require multi-factor authentication for Azure management’ we need to make sure our query is accurate. If we right-click on our policy and do the built-in ‘Include’ functionality in Sentinel:
It gives us the following query:
SigninLogs
| project ConditionalAccessPolicies
| where ConditionalAccessPolicies[3].displayName == "CA006: Require multi-factor authentication for Azure management"
We can see in this query that we are looking for when ConditionalAccessPolicies[3].displayName == “CA006: Require multi-factor authentication for Azure management”. The [3] indicated shows that we are looking for the 4th object in our array (we start counting at 0). So, what happens when someone fails this policy? It will move up the JSON array into position 0, and our query won’t catch it.
So how do we deal with these kinds of data? I present to you, mv-expand and mv-apply.
mv-expand
mv-expand, or multi-value expand, at its most basic, takes a dynamic array of data and expands it out to multiple rows. When we use mv-expand, KQL expands out the dynamic data, and simply duplicates any non-dynamic data. Leaving us with multiple rows to use in our queries.
mv-expand is essentially the opposite of summarize operators such as make_list and make_set. With those we are creating arrays, mv-expand we are reversing that, and expanding arrays.
As an example, let’s find the sign-in data for my account. In the last 24 hours, I have had 3 sign-ins into this tenant.
Within each of those, as above, we have a heap of policies that are evaluated.
I have cut the screenshot off for the sake of brevity, but I can tell you that in this tenant 22 policies are evaluated on each sign in. Now to see what mv-expand does, we add that to our query.
If we run our query, we will see each policy will be expanded out to a new record. The timestamp, location and username are simply duplicated, because they are not dynamic data. In my tenant, I get 22 records per sign in, one for each policy.
If we look at a particular record, we can see the Conditional Access policy is no longer positional within a larger array, because we have a separate record for each entry.
Now, if we are interested in our same “CA006: Require multi-factor authentication for Azure management” policy, and any events for that. We again do our right-click ‘Include’ Sentinel magic.
We will get the following query
SigninLogs
| project TimeGenerated,UserPrincipalName, Location, ConditionalAccessPolicies
| mv-expand ConditionalAccessPolicies
| where ConditionalAccessPolicies.displayName == "CA006: Require multi-factor authentication for Azure management"
This time our query no longer has the positional [3] we saw previously. We have expanded our data out and made it more consistent to query on. So, this time if we run our query, we will get a hit for every time the policy name is “CA006: Require multi-factor authentication for Azure management”, regardless of where in the JSON array it is. When we run that query, we get 3 results, as we would expect. One policy hit per sign in for the day.
Once you have expanded your data out, you can then create your hunting rules knowing the data is in a consistent location. So, returning to our original use case, if we want to find out where this particular policy is failing, this is our final query:
So, we have used mv-expand to ensure our data is consistent, and then looked for failures on that particular policy.
And we can see, we have hits on that new hunting query.
mv-apply
mv-apply, or multi-value apply adds to mv-expand, by allowing you to create a sub-query, and then returning the results. So, what does that actually mean? mv-apply actually runs mv-expand initially but gives us more freedom to create an additional query before returning the results. mv-expand is kind of like a hammer, we will just expand everything out and deal with it later. mv-apply gives us the ability to filter and query the expanded data, before returning it.
The syntax for mv-apply can be a little tricky to start with. To make things easy, let’s use our same data once again. Say we are interested in the Conditional Access stats for any policy that references ‘Azure’ or ‘legacy’ (for legacy auth), or any policy that has failures associated with it.
We could do an mv-expand as seen earlier, or we can use mv-apply to create that query during the expand.
SigninLogs
| project TimeGenerated,UserPrincipalName, Location, ConditionalAccessPolicies
| mv-apply ConditionalAccessPolicies on
(
where ConditionalAccessPolicies.displayName has_any ("Azure","legacy") or ConditionalAccessPolicies.result == "failure"
| extend CADisplayName=tostring(ConditionalAccessPolicies.displayName)
| extend CAResult=tostring(ConditionalAccessPolicies.result)
)
| summarize count() by CADisplayName, CAResult
So, for mv-apply, we start with mv-apply on. After that we create our subquery. Our sub-query is defined in the ( and ) seen after mv-apply. Interestingly, and quite unusual for KQL, is that the first line of the sub query does not require a | to precede it. Subsequent lines within the subquery do require it, as usual with KQL.
In this query we are looking for any policy names with ‘Azure’ or ‘legacy’ in them, or where the result is a failure. Then our query says if there is match on any of those conditions, then extend out our display name and result to new columns. Then finally we can summarize our data to provide some stats.
We are returned only the stats for matches of our sub-query. Either where the policy name has ‘Azure’ or ‘legacy’ or where the result is a failure.
Think of mv-apply as the equivalent of a loop statement through your expanded data. As it runs through each loop or row of data, it applies your query to each row.
It is important to remember order of operations when using mv-apply, if you summarize data inside the mv-apply ‘loop’ it will look much different to when you do it after the mv-apply has finished. Because it is within the ‘loop’, it will summarize it for every row of expanded data.
mv-apply is particularly valuable when dealing with JSON arrays that have additional arrays within them. You can mv-apply multiple times to get to the data you are interested in. On each loop, you can filter your query. Using a different data set, we can see an example of this. In the Azure AD audit logs, there is very often a quite generic event called ‘Update user’. This can be triggered on numerous things: name or licensing changes, email address updates or changes to MFA details etc.
In a lot of Azure AD audit logs, the interesting data is held in the ‘targetResources’ field. However, beneath that is a field called ‘modifiedProperties’. The modifiedProperties field has the detail of what actually changed on the user.
AuditLogs
| where TimeGenerated > ago(90d)
| where TargetResources has "PhoneNumber"
| where OperationName has "Update user"
| where TargetResources has "StrongAuthenticationMethod"
| extend InitiatedBy = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend UserPrincipalName = tostring(TargetResources[0].userPrincipalName)
| extend targetResources=parse_json(TargetResources)
| mv-apply tr = targetResources on (
extend targetResource = tr.displayName
| mv-apply mp = tr.modifiedProperties on (
where mp.displayName == "StrongAuthenticationUserDetails"
| extend NewValue = tostring(mp.newValue)
))
| project TimeGenerated, NewValue, UserPrincipalName,InitiatedBy
| mv-expand todynamic(NewValue)
| mv-expand NewValue.[0]
| extend AlternativePhoneNumber = tostring(NewValue.AlternativePhoneNumber)
| extend Email = tostring(NewValue.Email)
| extend PhoneNumber = tostring(NewValue.PhoneNumber)
| extend VoiceOnlyPhoneNumber = tostring(NewValue.VoiceOnlyPhoneNumber)
| project TimeGenerated, UserPrincipalName, InitiatedBy,PhoneNumber, AlternativePhoneNumber, VoiceOnlyPhoneNumber, Email
| where isnotempty(PhoneNumber)
| summarize ['Count of Users']=dcount(UserPrincipalName), ['List of Users']=make_set(UserPrincipalName) by PhoneNumber
| sort by ['Count of Users'] desc
In this example, we use mv-apply to find where the displayName of the modifiedProperties is ‘StrongAuthenticationUserDetails’. This indicates a change to MFA details, perhaps a new phone number has been registered. This particular query then looks for when it is indeed a phone number change. It then summarizes the number of users registered to the same phone number. This query is looking for Threat Actors that are registering the same MFA number to multiple users.
By using a ‘double’ mv-apply, we filter out all the ‘Update user’ events that we aren’t interested in, and focus down on the ‘StrongAuthenticationUserDetails’ events. We don’t get updates to say licensing events, that would be captured more broadly in an ‘Update user’ event.
Summary
mv-apply and mv-expand are just a couple of the ways to extract dynamic data in KQL. There are additional operators, such as bag_unpack, and even operators for other data types, such as parse_xml. I find myself coming constantly back to mv-expand and mv-apply, mostly because of the ubiquitousness of JSON in security products.
If you follow my Twitter or GitHub account, you know that I recently completed a #365daysofKQL challenge. Where I shared a hunting query each day for a year. To round out that challenge, I wanted to share what I have learnt over the year. Like any activity, the more you practice, the better you become at it. At about day 200, I went back to a lot of queries and re-wrote them with things I had picked up. I wanted to make my queries easier to read and more efficient. Some people also asked if I was ever short of ideas. I never had writers block or struggled to come up with ideas. I am a naturally curious person, so looking through data sets is interesting to me. On top of that there is always a new threat, or a new vulnerability around. Threat actors come up with new tactics and you can then try and find those. Then you can take those queries and apply them to other data sets. On top of that, vendors, especially Microsoft are always adding new data in. There is always something new to look at.
I have also learned that KQL is a very repeatable language. You can build ‘styles’ of queries, and then re-use those on different logs. If you are looking for the first time something happened. Or if something happened at a weird time of the day. That becomes a query pattern. Sure, the content of the data you are looking at may change. The structure of the query remains the same.
So without further ado, what I have learnt writing 365 queries.
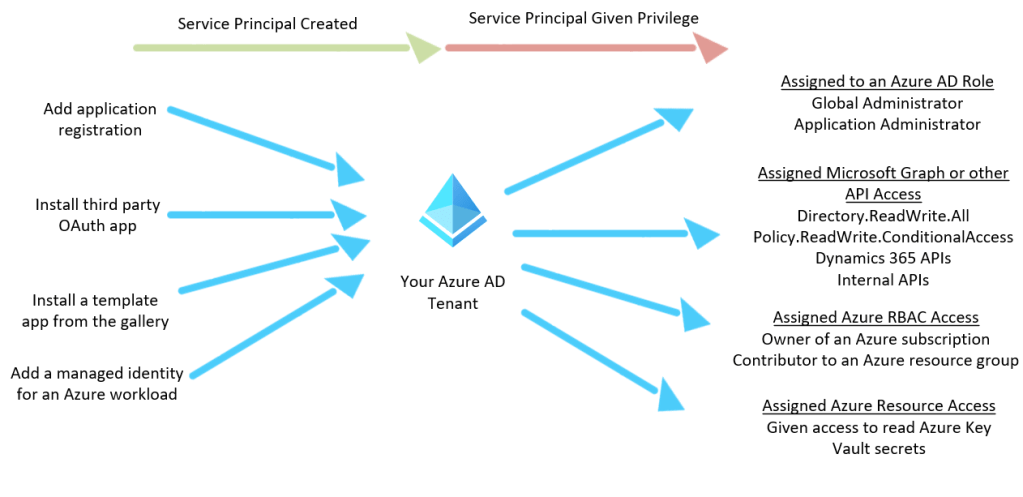
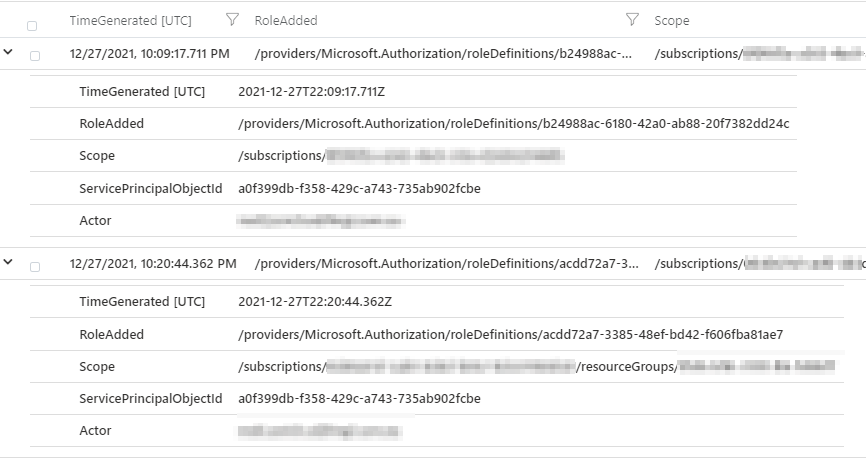
Use your own account and privilege to generate alerts
If you follow InfoSec news, there is always a new activity you may want to alert on. As these new threats are uncovered, hopefully you don’t find them in your environment. But you want to be ready. I find it valuable to look at the details and attempt to create those logs and then go find them. From there you can tidy your query up so it is accurate. You don’t want to run malicious code or do anything that will cause an outage. You can certainly simulate the adversary though. Take for instance consent phishing. You don’t want to actually install a malicious app. You can register an app manually though. You could then query your Azure AD audit logs to find that event. Start really broadly with just seeing what you have done with your account.
AuditLogs
| where InitiatedBy contains "youruseraccount"
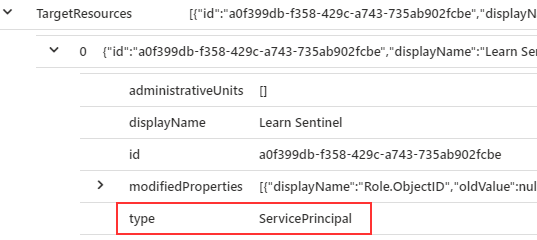
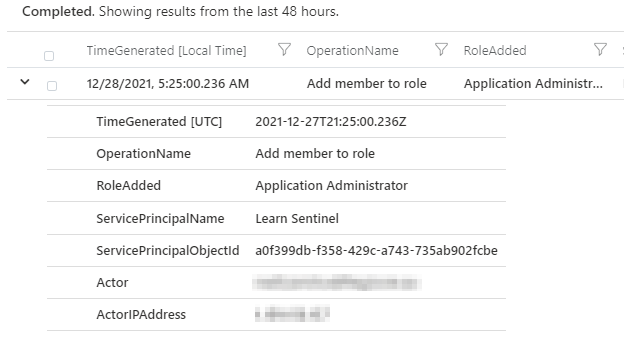
You will see an event ‘Add service principal’, that is what we are after. In the Azure AD audit log, this is a ‘OperationaName’. So we can then tune our query. We know we want any ‘Add service principal’ events. We can also look through and see where our username is and our IP. So we can extend those to new columns. For our actual query we don’t want to include our user account, so take that out.
AuditLogs
| where OperationName == "Add service principal"
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend IPAddress = tostring(parse_json(tostring(InitiatedBy.user)).ipAddress)
| project TimeGenerated, OperationName, Actor, IPAddress
Now we have a query that detects each time someone adds a service principal. If someone is consent phished, this will tell us. Then we can investigate. We can then delete our test service principal out to clean up our tenant.
Look for low volume events
One of the best ways to find interesting events, is to find those that are low volume. While not always malicious they are generally worth investigating. Using our Azure AD audit log example, it is simple to find low volume events.
AuditLogs
| summarize Count=count() by OperationName, LoggedByService
| sort by Count asc
This will return the count of all the operations in Azure AD for you, and list those with the fewest hits first. It will also return which service in Azure AD triggered it. Your data will look different to mine, but as an example you may see.
Now you look at this list and you can see if any interest you. Maybe you want to know each time an Azure AD Conditional Policy is updated. We can see that event. Or when a BitLocker key is read. You can then take those operations and start building your queries out.
You can do the same on other data sources, like Office 365.
OfficeActivity
| summarize Count=count() by Operation, OfficeWorkload
| sort by Count asc
The data is a little different, we have Operation instead of OperationName. And we have OfficeWorkload instead of LoggedByService. But the pattern is the same. This time we are returned low count events from the Office 365 audit log.
Look for the first time something occurs and new events
This is a pattern I love using. We can look at new events in our environment that we haven’t previously seen. Like me, I am sure you struggle with new alerts, or new log sources to your environment. Let KQL do it for you. These queries are simple and easily re-useable. Again, let’s use our Azure AD audit log as an example.
let existingoperations=
AuditLogs
| where TimeGenerated > ago(180d) and TimeGenerated < ago(7d)
| distinct OperationName;
AuditLogs
| where TimeGenerated > ago(7d)
| summarize Count=count() by OperationName, Category
| where OperationName !in (existingoperations)
| sort by Count desc
First we cast a variable called ‘existingoperations’. That queries our audit log for events between 180 and 7 days ago. From that list, we just list each distinct OperationName. That becomes our list of events that have already occurred.
We then re-query the audit log again, this time just looking at the last week. We take a count of all the operations. Then we exclude the ones we already knew about from our first query. Anything remaining is new to our environment. Have a look through the list and see if anything is interesting to you. If it is, then you can write your specific query.
Look for when things stop occurring
The opposite to new events occurring is when events stop occurring. One of the most common use cases for this kind of query is tell me when a device is no longer sending logs. To keep on top of detections we need to make sure devices are still sending their logs.
SecurityEvent
| where TimeGenerated > ago (1d)
| summarize ['Last Record Received'] = datetime_diff("minute", now(), max(TimeGenerated)) by Computer
| project Computer, ['Last Record Received']
| where ['Last Record Received'] >= 60
| order by ['Last Record Received'] desc
This query will find any device that hasn’t send a security event log in over 60 minutes in the last day. Maybe the machine is offline, or there are network issues? Worth checking out either way.
We can use that same concept to find all kinds of things. How about user accounts no longer signing in? That is also something that is no longer occurring. This time though, it isn’t really an ‘alert’. It is great way to clean up user accounts though.
SigninLogs
| where TimeGenerated > ago (365d)
| where ResultType == 0
| where isnotempty(UserType)
| summarize arg_max(TimeGenerated, *) by UserPrincipalName
| where TimeGenerated < ago(60d)
| summarize
['Inactive Account List']=make_set(UserPrincipalName),
['Count of Inactive Accounts']=dcount(UserPrincipalName)
by UserType, Month=startofmonth(TimeGenerated)
| sort by Month desc, UserType asc
We can find all our user accounts, both members and guests, that haven’t signed in for more than 60 days. We can also retrieve the last month they last accessed our tenant.
Look for when things occur at strange times
KQL is amazing at dealing with time data. We can include any kind of logic into our queries to detect only during certain times. Or on certain days. Or a combination of both. An event that happens over a weekend of outside of working hours perhaps requires a faster response. A couple of good examples this are Azure AD Privileged Identity Management and adding a service principal to Azure AD. Maybe Monday to Friday, during business hours these activities are pretty normal. Outside of that though? We can tell KQL to focus on those times.
let Saturday = time(6.00:00:00);
let Sunday = time(0.00:00:00);
AuditLogs
// extend LocalTime to your time zone
| extend LocalTime=TimeGenerated + 5h
| where LocalTime > ago(7d)
// Change hours of the day to suit your company, i.e this would find activations between 6pm and 6am
| where hourofday(LocalTime) !between (6 .. 18) or hourofday(LocalTime)
| where OperationName == "Add member to role completed (PIM activation)"
| extend User = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend ['Azure AD Role Name'] = tostring(TargetResources[0].displayName)
| project LocalTime, User, ['Azure AD Role Name'], ['Activation Reason']=ResultReason
This query searches for PIM activations on weekends or between 6pm and 6am during the week. You can then re-use that same logic to detect on other things during those times.
Summarize to make sense of large data sets
I have written about data summation previously. If you send data to Sentinel chances are you will have a lot of it. Even a small Azure AD tenant generates a lot of data. 150 devices in Defender is a lot of logs. Summarizing data in KQL is both easy and useful. Maybe you are interested in what your users are doing when they connect to other tenants. Each log entry on its own probably isn’t exciting. If you allow that activity then it isn’t really a detection. You wouldn’t generate an alert each time someone accessed another tenant. You may be interested in other tenants more broadly though.
SigninLogs
| where TimeGenerated > ago(30d)
| where UserType == "Guest"
| where AADTenantId == HomeTenantId
| where ResourceTenantId != AADTenantId
| summarize
['Count of Applications']=dcount(AppDisplayName),
['List of Applications']=make_set(AppDisplayName),
['Count of Users']=dcount(UserPrincipalName),
['List of Users']=make_set(UserPrincipalName)
by ResourceTenantId
| sort by ['Count of Users'] desc
This query looks for each ResourceTenantId. Which is the Id of the tenant your users are accessing. For each tenant, it returns what applications, a count of applications, which users and a count of users accessing it. Maybe you see in that data there is one tenant that your users are accessing way more than any other. It may be worth investigating why or adding additional controls to that tenant via cross-tenant settings.
Another good example, we can use Defender for Endpoint logs for all kinds of great info. Take for example LDAP and LDAPS traffic. Hopefully you want to migrate to LDAPS, which is more secure. If you look at each LDAP event to see what’s in your environment, it will be overwhelming. Chances are you will get thousands of results a day.
DeviceNetworkEvents
| where ActionType == "InboundConnectionAccepted"
| where LocalPort in ("389", "636", "3269")
| summarize
['Count of Inbound LDAP Connections']=countif(LocalPort == 389),
['Count of Distinct Inbound LDAP Connections']=dcountif(RemoteIP, LocalPort == 389),
['List of Inbound LDAP Connections']=make_set_if(RemoteIP, LocalPort == 389),
['Count of Inbound LDAPS Connections']=countif(LocalPort in ("636", "3269")),
['Count of Distinct Inbound LDAPS Connections']=dcountif(RemoteIP, LocalPort in ("636", "3269")),
['List of Inbound LDAPS Connections']=make_set_if(RemoteIP, LocalPort in ("636", "3269"))
by DeviceName
| sort by ['Count of Distinct Inbound LDAP Connections'] desc
This query looks at all those connections, and summarizes it down so it’s easier to read. For each device on our network we summarize those connections. For each we get the total count of connections, a count of distinct endpoints and the list of endpoints. Maybe we have thousands and thousands of events per day. When we run this query though, it is really just a handful of noisy machines. Suddenly that LDAPS migration isn’t so daunting.
Change your data summary to change context
Once you have written your queries that summarize your data, you can then change the context easily. You can basically re-use your work and see something different in the same data. Take these two queries.
DeviceNetworkEvents
| where TimeGenerated > ago(30d)
| where ActionType == "ConnectionSuccess"
| where RemotePort == "3389"
//Exclude Defender for Identity that uses an initial RDP connection to map your network
| where InitiatingProcessCommandLine <> "\"Microsoft.Tri.Sensor.exe\""
| summarize
['RDP Outbound Connection Count']=count(),
['RDP Distinct Outbound Endpoint Count']=dcount(RemoteIP),
['RDP Outbound Endpoints']=make_set(RemoteIP)
by DeviceName
| sort by ['RDP Distinct Outbound Endpoint Count'] desc
This first query finds which devices in your environment connect to the most other endpoints via RDP. These devices are a target for lateral movement as they have more credentials stored on them.
DeviceLogonEvents
| where TimeGenerated > ago(30d)
| project DeviceName, ActionType, LogonType, AdditionalFields, InitiatingProcessCommandLine, AccountName, IsLocalAdmin
| where ActionType == "LogonSuccess"
| where LogonType == "Interactive"
| where AdditionalFields.IsLocalLogon == true
| where InitiatingProcessCommandLine == "lsass.exe"
| summarize
['Local Admin Count']=dcountif(DeviceName,IsLocalAdmin == "true"),
['Local Admins']=make_set_if(DeviceName, IsLocalAdmin == "true")
by AccountName
| sort by ['Local Admin Count'] desc
This second query looks for logon events from your devices. It finds the users that have accessed the most devices as a local admin. Which will find us which accounts are targets for lateral movement.
So two very similar queries. Both provide information about lateral movement targets. However, we change our summary target so we get unique context in the results.
Try to write queries looking for behavior rather than static IOCs
This is another topic I have written about before. We want to, where possible, create queries based on behavior rather than specific IOCs. While IOCs are useful in threat hunting, they are likely to change quickly.
Say for example you read a report about a new threat. It says in there that the threat actor used certutil.exe to connect to 10.10.10.10.
Easy, we will catch if someone uses certutil.exe to connect to 10.10.10.10.
What if the IP changes though? Now the malicious server is on 10.20.20.20. Our query no longer will catch it. So instead go a little broader, and catch the behavior.
The query now detects any usage of certutil.exe connecting to any public endpoint. I would suspect this is very rare behavior in most environments. Now it is irrelevant what the IP is, we will catch it.
Use your data to uplift your security posture
Not every query you write needs to be about threat detection. Of course we want to catch attackers. We can however use the same data to provide amazing insights about security posture. Take for instance Azure Active Directory sign in logs. We can detect when someone signs in from a suspicious country. Just as useful though is all the other data contained in those logs. We can see visibility into conditional access policies, legacy authentication, MFA events, device and location information.
Legacy authentication is always in the news. There is no way to put MFA in front of it, so it is the first door attackers knock on. We can use our sign in data to see just how big a legacy authentication problem we have.
SigninLogs
| where TimeGenerated > ago(30d)
| where ResultType == 0
| where ClientAppUsed !in ("Mobile Apps and Desktop clients", "Browser")
| where isnotempty(ClientAppUsed)
| evaluate pivot(ClientAppUsed, count(), UserPrincipalName)
This query finds any apps that make up legacy authentication. Those that aren’t a modern app or a browser. Then it creates a easy to read pivot table. The table will show each user that has connected with legacy authentication. For each app it will give you a count. Maybe you have 25000 legacy authentication connections in a month, which seems impossible to address. When you look at it closer though, it may just be a few dozen users.
Similarly, you could try to improve your MFA posture.
SigninLogs
| where TimeGenerated > ago(30d)
//You can exclude guests if you want, they may be harder to move to more secure methods, comment out the below line to include all users
| where UserType == "Member"
| mv-expand todynamic(AuthenticationDetails)
| extend ['Authentication Method'] = tostring(AuthenticationDetails.authenticationMethod)
| where ['Authentication Method'] !in ("Previously satisfied", "Password", "Other")
| where isnotempty(['Authentication Method'])
| summarize
['Count of distinct MFA Methods']=dcount(['Authentication Method']),
['List of MFA Methods']=make_set(['Authentication Method'])
by UserPrincipalName
//Find users with only one method found and it is text message
| where ['Count of distinct MFA Methods'] == 1 and ['List of MFA Methods'] has "text"
This example looks at each user that has used MFA to your Azure AD tenant. For each, it creates a set of different MFA methods used. For example, maybe they have used a push notification, a phone call and a text. They would have 3 methods in their set of methods. Now we add a final bit of logic. We find out where a user only has a single method, and that method is text. We can take this list and do some education with those users. Maybe show them how much easier a push notification is.
Use your data to help your users have a better experience
If you have onboarded data to Sentinel, or use Advanced Hunting, you can use that data to help your users out. While we aren’t measuring performance of computers or things like that, we can still get insights where they may be struggling.
Take for example Azure AD self service password reset. When a user goes through that workflow they can get stuck in a few spots, and we can find it. Each attempt at SSPR is linked by the same Correlation Id in Azure AD. So we can use that Id to make a list of actions that occurred during that attempt.
AuditLogs
| where LoggedByService == "Self-service Password Management"
| extend User = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend ['User IP Address'] = tostring(parse_json(tostring(InitiatedBy.user)).ipAddress)
| sort by TimeGenerated asc
| summarize ['SSPR Actions']=make_list(ResultReason) by CorrelationId, User, ['User IP Address']
If you have a look, you will see things like user submitted new password, maybe the password wasn’t strong enough. Hopefully a successful password reset at the end. Now if we want to help our users out we can dig into that data. For instance, we can see when a user tries to SSPR but doesn’t have an authentication method listed. We could reach out to them and help them get onboarded.
AuditLogs
| where LoggedByService == "Self-service Password Management"
| extend User = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend ['User IP Address'] = tostring(parse_json(tostring(InitiatedBy.user)).ipAddress)
| sort by TimeGenerated asc
| summarize ['SSPR Actions']=make_list(ResultReason) by CorrelationId, User, ['User IP Address']
| where ['SSPR Actions'] has "User's account has insufficient authentication methods defined. Add authentication info to resolve this"
| sort by User desc
If a user puts in a password that doesn’t pass complexity requirements we can see that too. We could query when the same user has tried 3 or more times to come up with a new password and is rejected. We all understand how frustrating that can be. They would definitely appreciate some help and you could maybe even use it as a change to move them to Windows Hello for Business, or passwordless. If you support those, of course.
AuditLogs
| where LoggedByService == "Self-service Password Management"
| extend User = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend ['User IP Address'] = tostring(parse_json(tostring(InitiatedBy.user)).ipAddress)
| sort by TimeGenerated asc
| summarize ['SSPR Actions']=make_list_if(ResultReason, ResultReason has "User submitted a new password") by CorrelationId, User, ['User IP Address']
| where array_length(['SSPR Actions']) >= 3
| sort by User desc
Consistent data is easy to read data
One of the hardest things about writing a query is just knowing where to look for those logs. The second hardest thing is dealing with data inconsistencies. If you have log data from many vendors, the data will be completely different. Maybe one firewall calls a reject a ‘deny’, another calls it ‘denied’, then your last firewall calls it ‘block’. They are the same in terms of what the firewall did. You have to account for the data differences though. If you don’t, you may miss results.
You can rename tables or even extend your own whenever you want. You can do that to unify your data, or just make it easier to read.
Say you have two pretend firewalls, one is a CheckPoint and one a Cisco. Maybe the CheckPoint shows the result as a column called ‘result’. The Cisco however uses ‘Outcome’.
You can simply rename one of them.
CheckPointLogs_CL
| project-rename Outcome=result
In our CheckPoint logs we have just told KQL to rename the ‘result’ field to ‘Outcome’
You can even do this as part of a ‘project’ at the end of your query if you want.
We have renamed our fake columns to Source IP, Destination IP, Port, Outcome.
If we do the same for our Cisco logs, then our queries will be so much easier to write. Especially if you are joining between different data sets. They will also be much easier to read both for you and anyone else using them.
Be careful of case sensitivity
Remember that a number of string operators are KQL are case sensitive. There is a really useful table here that outlines the different combinations. Using a double equals sign in a query, such as UserPrincipalName == “reprise99@learnsentinel.com” is efficient. Remember though, that if my UserPrincipalName was reprise99@learnSentinel.com with a capital S, it wouldn’t return that result. It is a balancing act between efficiency and accuracy. If you are unsure about the consistency of your data, then stick with case insensitive operators. For example. UserPrincipalName =~ “reprise99@learnsentinel.com” would return results regardless of sensitivity.
This is also true for a not equals operator. != is case sensitive, and !~ is not.
You also have the ability to use either tolower() or toupper() to force a string to be one or the other.
This can help you make your results more consistent.
Use functions to save you time
If you follow my Twitter you know that I write a lot of functions. They are an amazing timesaver in KQL. Say you have written a really great query that tidies data up. Or one that combines a few data sources for you. Save it as function for next time.
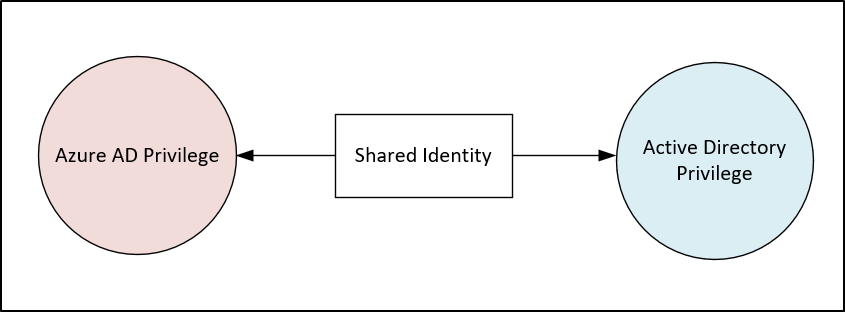
My favourite functions are the ones that unify different data sources that are similar operations. Take adding or removing users to groups in Active Directory and Azure Active Directory. You may be interested in events from both environments. Unfortunately the data structure is completely different. Active Directory events come in via the SecurityEvent table. Whereas, Azure Active Directory events are logged to the AuditLogs table.
This function I wrote combines the two and unifies the data. So you can search for ‘add’ events, and it will bring back when users were added to groups in either environment. When you deploy this function you can easily create queries such as.
GroupChanges
| where GroupName =~ "Sentinel Test Group"
It will find groups named ‘Sentinel Test Group’ in either AD or AAD. It will return you who was added or removed, who did it and which environment the group belongs to. The actual KQL under the hood does all the hard work for you.
let aaduseradded=
AuditLogs
| where OperationName == "Add member to group"
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend Target = tostring(TargetResources[0].userPrincipalName)
| extend GroupName = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[1].newValue)))
| extend GroupID = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[0].newValue)))
| where isnotempty(Actor) and isnotempty(Target)
| extend Environment = strcat("Azure Active Directory")
| extend Action = strcat("Add")
| project TimeGenerated, Action, Actor, Target, GroupName, GroupID, Environment;
let aaduserremoved=
AuditLogs
| where OperationName == "Remove member from group"
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend GroupName = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[1].oldValue)))
| extend GroupID = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[0].oldValue)))
| extend Target = tostring(TargetResources[0].userPrincipalName)
| where isnotempty(Actor) and isnotempty(Target)
| extend Action = strcat("Remove")
| extend Environment = strcat("Azure Active Directory")
| project TimeGenerated, Action, Actor, Target, GroupName, GroupID, Environment;
let adchanges=
SecurityEvent
| project TimeGenerated, EventID, AccountType, MemberName, SubjectUserName, TargetUserName,TargetSid
| where AccountType == "User"
| where EventID in (4728, 4729, 4732, 4733, 4756, 4757)
| parse MemberName with * 'CN=' Target ',OU=' *
| extend Action = case(EventID in ("4728", "4756", "4732"), strcat("Add"),
EventID in ("4729", "4757", "4733"), strcat("Remove"), "unknown")
| extend Environment = strcat("Active Directory")
| project
TimeGenerated,
Action,
Actor=SubjectUserName,
Target,
GroupName=TargetUserName,
GroupID =TargetSid,
Environment;
union aaduseradded, aaduserremoved, adchanges
It may look complex, but it isn’t. We are just taking data that isn’t consistent and tidying it up. In AD when we add a user to a group, the group name is actually stored as ‘TargetUserName’ which isn’t very intuitive. So we rename it to GroupName, and we do the same for Azure AD. The Actor and Target are named different in AD and AAD, so let’s just rename them. Then we just add a new column for environment.
KQL isn’t just for Microsoft Sentinel
Not everyone has the budget to use Microsoft Sentinel, and I appreciate that. If you have access to Advanced Hunting you have access to an amazing amount of info there too. Especially if you have an Azure AD P2 license. The following data is available for you, at no additional cost to your existing Defender and Azure AD licensing.
Device events – such as network or logon events.
Email events – emails received or sent, attachment and URL info.
Defender for Cloud Apps – all the logs from DCA and any connected apps.
Alerts – all the alert info from other Defender products.
Defender for Identity – if you use Defender for Identity, all that info is there.
Azure AD Sign In Logs – if you have Azure AD P2 you get all the logon data. For both users and service principals.
The data structure between Sentinel and Advanced Hunting isn’t an exact match, but it is pretty close. Definitely get in there and have a look.
Visualize for impact
A picture is worth a thousand words. With all this data in your tenant you can use visualizations for all kinds of things. You can look for anomalies, try to find strange attack patterns. Of course they are good to report up to executives too. Executive summaries showing total email blocked, or credential attacks stopped always play well. When building visualizations, I want them to explain the data with no context needed. They should be straight forward and easy to understand.
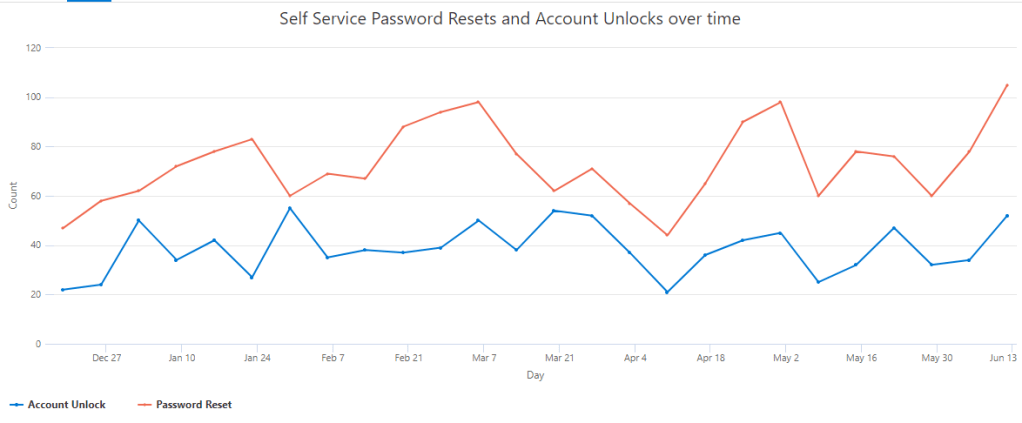
A couple of examples I really think are valuable. The first shows you successful self service password reset and account unlock events. SSPR is such a great time saver for your helpdesk. It is also often more secure than a traditional password reset as the helpdesk can’t be socially engineered. It is also a great visualization to report upward. It is a time saver, and therefore money saver for your helpdesk, and it’s more secure. Big tick.
AuditLogs
| where TimeGenerated > ago (180d)
| where OperationName in ("Reset password (self-service)", "Unlock user account (self-service)")
| summarize
['Password Reset']=countif(OperationName == "Reset password (self-service)" and ResultDescription == "Successfully completed reset."),
['Account Unlock']=countif(OperationName == "Unlock user account (self-service)" and ResultDescription == "Success")
by startofweek(TimeGenerated)
| render timechart
with (
ytitle="Count",
xtitle="Day",
title="Self Service Password Resets and Account Unlocks over time")
With KQL we can even rename our axis and title in the query, copy and paste the picture. Send it to your boss, show him how amazing you are. Get a pay increase.
And a similar query, showing password vs passwordless sign ins into your tenant. Maybe your boss has heard of passwordless, or zero trust. Show him how you are tracking to help drive change.
SigninLogs
| where TimeGenerated > ago (180d)
| mv-expand todynamic(AuthenticationDetails)
| project TimeGenerated, AuthenticationDetails
| extend AuthMethod = tostring(AuthenticationDetails.authenticationMethod)
| summarize
Passwordless=countif(AuthMethod in ("Windows Hello for Business", "Passwordless phone sign-in", "FIDO2 security key", "X.509 Certificate")),
Password=countif(AuthMethod == "Password")
by bin(TimeGenerated, 1d)
| render timechart with (title="Passwordless vs Password Authentication", ytitle="Count")
Don’t be afraid of making mistakes or writing ‘bad’ queries
For normal logs in Sentinel, there is no cost to run a query. For Advanced Hunting, there is no cost to query. Your licensing and ingestion fees give you the right to try as much as you want. If you can’t find what you are looking for, then start broadly. You can search across all your data easily.
search "reprise99"
It may take a while, but you will get hits. Then find out what tables they are in. Then narrow down your query. I think of writing queries like a funnel. Start broad, then get more specific until you are happy with it.
In my day to day work and putting together 365 queries to share, I have run just under 60,000 queries in Sentinel itself. Probably another 10,000 or more in Advanced Hunting. A lot of them would have caused errors initially. That is how you will learn! Like anything, practice makes progress.
As I transition to a new role I will keep sharing KQL and other security resources that are hopefully helpful to people. The feedback I have had from everyone has been amazing. So I appreciate you reading and following along.
This was how many queries I ran per day this year!
If you are looking at using Microsoft Sentinel, then Active Directory is likely high on your list of sources to onboard. If you already use it, you probably spend a fair bit of time digging through Active Directory logs. Despite Microsoft’s push to Azure Active Directory, on premise Active Directory is still heavily used. You may have migrated off it for cloud workloads, but chances are you still use it on premises. Attacking and defending Active Directory is a such a broad subject it is basically a speciality within cyber security itself.
You can onboard Active Directory logs a number of ways, they all have their pros and cons. The purpose of this post is to show you the different options and hopefully you can make an informed decision of which way to go.
You may have heard reference to the Log Analytics agent, or the Azure Monitor Agent. You may already be licensed for Defender for Identity too. Do I need these all? Can I use multiple?
Let’s break it down.
So in general to ship logs to Sentinel from Active Directory you will need an agent installed. You could be doing native Windows Event Forwarding, but to keep it simple, let’s look at the agent options.
The events written to Sentinel will be an exact match for what are logged on your domain controllers. If EventId 4776 is logged on the server, Sentinel will retain an exact copy. These are written to the SecurityEvent table.
Which EventIds you ingest depends on what tier you choose here.
There is no way to customize the logging apart from those predefined levels.
The cost will depend what logging level you choose. If you choose all events and you have a busy domain, it can be significant.
Events will be in near real time.
This agent is end of life in 2024.
Often also referred to as the Microsoft Monitoring Agent.
The events written to Sentinel will be an exact match for what are logged on your domain controllers. If EventId 4776 is logged on the server, Sentinel will retain an exact copy. These are written to the SecurityEvent table.
Which EventIds you ingest you can fully customize. This is done via Data Collection Rules. If you only want specific EventIds you can do that. You can even filter EventIds on specific fields, like process names.
Non Azure VM workloads need to be enrolled into Azure Arc to use this agent. This includes on premises servers, or virtual machines in other clouds.
The cost will depend what logging level you configure via your rules.
Events will be in near real time.
At the time of writing this post, the Azure Monitor agent is still missing some features compared to the Log Analytics agents. View the limitations here.
If you have the Defender for Identity agent installed you can leverage that in Sentinel.
You can send two types of data from the Defender for Identity service to Sentinel.
Alerts from Defender for Identity are written to the SecurityAlert table.
For instance, a reconnaissance or golden ticket usage alert. This is only the alert and associated entities. No actual logs are sent to this table.
This data is free to ingest to Sentinel. You can enable it via the ‘Microsoft Defender for Identity’ data connector.
Summarized event data can also be written back to Sentinel. These are the same logs that appear in Advanced Hunting if you have previously used that. They are –
IdentityLogonEvents – will show you logon events, both in Active Directory and across Office 365.
IdentityDirectoryEvents – will show you directory events, such as group membership changing, or an account being disabled.
IdentityQueryEvents – will show you query events, such as SAMR or DNS queries.
This data is not free to ingest. You can enable it via the ‘Microsoft 365 Defender’ data connector under ‘Microsoft Defender for Identity’
There is no ability to customize these events. They will change or update only as the Defender for Identity product evolves.
The cost will depend on the size of your environment of course. It should be significantly less than raw logs however. We will explore this soon.
There is a delay in logs as they are sent to the Defender for Identity service, then to Sentinel.
So the first two agents are pretty similar. The Azure Monitor agent is the natural evolution of the Log Analytics agent. Using the new one gives you the ability to customize your logs, which is a huge benefit. It is also easy to have different collection rules. You could take all the logs from your critical assets. Then you could just take a subset of events from other assets. You also get the added Azure Arc capability if you want to leverage any of it.
Data Coverage
For the Log Analytics and Azure Monitor agents the coverage is straight forward. Whatever you configure you will ingest into Sentinel. For the Log Analytics agent, this will depend on which logging tier you select. For the Azure Monitor Agent it will depend on your Data Collection Rules.
For Defender for Identity it gets a little trickier. We have no control over the events that are sent to Sentinel. I imagine over time these change and evolve as the product does. The best way to check is to have a look at some of the actions that are being logged. You can run this query to summarize all the events in your tenant. This will also work in Advanced Hunting.
IdentityDirectoryEvents
| where TimeGenerated > ago(7d)
| summarize count()by ActionType
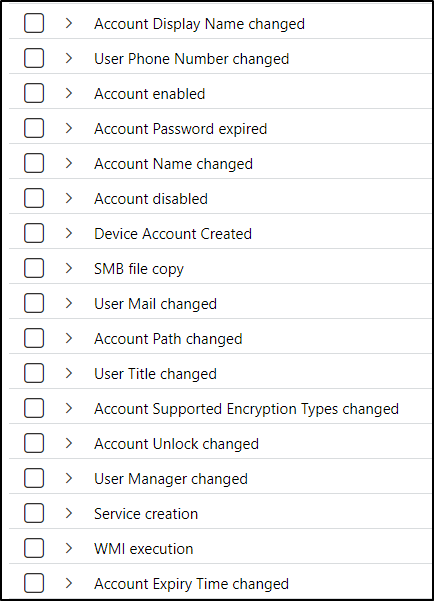
Here is a sample of a few of the events we see.
Some are the same as what we see with standard logs. Group membership changed, account password changed etc. The difference is we don’t see all the EventIds that make up these activities. These Defender for Identity events are similar to Azure Active Directory audit logs. We don’t see what is happening behind the scenes in Azure AD. We do see activities though, such as users being added to groups.
Just because you aren’t getting the raw logs, doesn’t mean it’s bad. In fact there are some things unique to these events we don’t get from actual domain controller logs. Defender for Identity is a really great service and we benefit from the correlation it does.
Have a look at some of these activities – encryption changes, WMI execution, there are many interesting findings. Potential lateral movement path identified is really great too. Defender for Identity is by no means BloodHound for mapping attack paths. It does still provide interesting insights though. Without Defender for Identity doing the hard work for you, you would need to write the logic yourself.
Data Size
Ingestion costs are always something to keep an eye on, and Active Directory logs can be noisy. With the Log Analytics agent your data costs will basically be inline with what tier of logging you choose. The higher the tier, and the larger your domain, the more it will ingest. The Azure Monitor agent is much the same. However you get the added benefit of being able to configure what logs you want. Given domain controllers are critical assets you are likely to want most EventIds though.
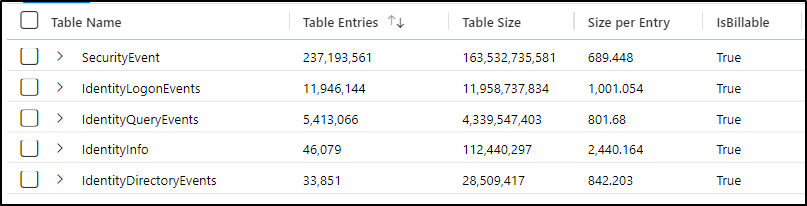
With Defender for Identity, it is different. It will only send back certain audit events. The size and complexity of your domain is still relevant though. The more audit events you generate, the more that will be ingested back to Sentinel. What may be more useful however is the relative size of the logs. Using KQL we can calculate the difference between normal logs and those from Defender for Identity. You may send non DCs to the same SecurityEvent table. If so, just include a filter in your query to only include DCs.
union withsource=TableName1 SecurityEvent, Identity*
| where TimeGenerated > ago(7d)
| where Computer contains "DC" or isempty( Computer)
| summarize Entries = count(), Size = sum(_BilledSize), last_log = datetime_diff("second",now(), max(TimeGenerated)), estimate = sumif(_BilledSize, _IsBillable==true) by TableName1, _IsBillable
| project ['Table Name'] = TableName1, ['Table Entries'] = Entries, ['Table Size'] = Size,
['Size per Entry'] = 1.0 * Size / Entries, ['IsBillable'] = _IsBillable, ['Last Record Received'] = last_log , ['Estimated Table Price'] = (estimate/(1024*1024*1024)) * 0.0
| order by ['Table Size'] desc
In a lab environment with a few DCs you can see a significant difference in size. Every environment will vary of course, but your Defender for Identity logs will be much smaller.
Log Delay
A key focus for you may be how quickly these logs arrive at Sentinel. As security people, some events are high enough risk we want to know instantly. When using either the Log Analytics or Azure Monitor agent, that happens within a few minutes. The event needs to be logged on the DC itself. Then sent to Sentinel. But it should be quick.
Events coming in from Defender for Identity first need to be sent to that service. Defender for Identity then needs to do its correlation and other magic. Then the logs need to be sent back to Sentinel. Over the last few days I have completed some regular activities. Then calculated how long it takes to go to Defender for Identity, then to Sentinel.
Adding a user to a group – took around 2.5 hours to appear in Sentinel on average.
Disabling a user – also took around 2.5 hours to appear in Sentinel.
Changing job title – took around 4 hours to appear in Sentinel.
These time delays may change depending on how often certain jobs run on the Microsoft side. The point is that they are not real time, so just be aware.
Query Differences
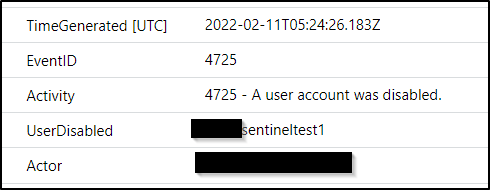
One of the biggest differences between the Log Analytics/Azure Monitor agent and Defender for Identity is data structure. For the Log Analytics and Azure Monitor agents the data is a copy of the log on your server. Take EventId 4725, a user account was disabled. That is going to look the same in Event Viewer as in Sentinel. We can use simple KQL to parse what we care about.
With Defender for Identity, the raw event data has been converted to an activity for us. We don’t need to search for specific EventIds. There is an ‘account disabled’ activity.
We can also see here the differences between what data we are returned. Defender for Identity just tells us that an account was disabled. It doesn’t tell us who did it. Whereas the logs taken from one of the other agents has far more information.
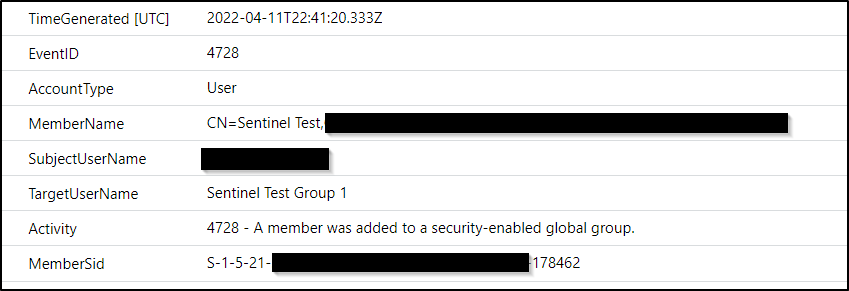
Interested in group membership changes? When you look at the logs straight from a domain controller there are lots of EventIds you will need. Active Directory tracks these differently depending on the type of group. EventId 4728 is when a user is added to a security-enabled global group. Then you will have a different EventId for a security-enabled local group. Then the same for group removals. And so on. We can capture them all with this query.
SecurityEvent
| project TimeGenerated, EventID, AccountType, MemberName, SubjectUserName, TargetUserName, Activity, MemberSid
| where EventID in (4728,4729,4732,4733,4756,4757)
In Defender for Identity, these events are rolled up to a single activity. It logs these as ‘Group Membership changed’. Regardless of group type or whether it was someone being added or removed. That means we can return all group changes in a single, simple query.
You may be thinking that the Defender for Identity logs are ‘worse’. That isn’t true, they are just different. They also provide you some insights over and above what you get from security events directly.
Defender for Identity does lateral movement path investigation. This won’t give you the insights of a tool like BloodHound. It can still be useful though. For example, you can find which of your devices or users have the most lateral movement paths identified.
IdentityDirectoryEvents
| where ActionType == "Potential lateral movement path identified"
| summarize arg_max(TimeGenerated, *) by ReportId
| summarize Count=count()by AccountUpn, DeviceName
| sort by Count desc
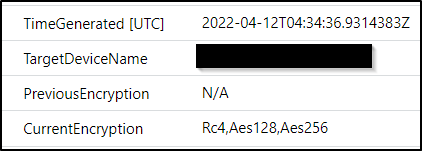
Events that are painful to find in regular logs can be simple to find in the Defender for Identity events. For instance when accounts have their encryption types changed. Parsing that from the security events is hard work. With the Defender for Identity events it is really simple.
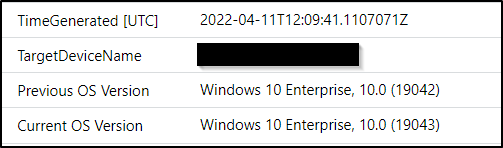
It will even show you when a device changes operating system version.
IdentityDirectoryEvents
| where ActionType == "Device Operating System changed"
| extend ['Previous OS Version'] = tostring(AdditionalFields.["FROM Device Operating System"])
| extend ['Current OS Version'] = tostring(AdditionalFields.["TO Device Operating System"])
| project TimeGenerated, TargetDeviceName, ['Previous OS Version'], ['Current OS Version']
Summary
Hopefully that sheds some light on the various options. If you need real time detection, then the only real option is the Log Analytics or Azure Monitor agent. The delay with logs being sent via Defender for Identity means you may be too late spotting malicious activity. Which of the agents you choose between the two is up to you.
If you need the ability to customize which logs you want, then the Azure Monitor agent is for you. Keep in mind for non Azure workloads, you will require the machine enrolled to Azure Arc.
The Log Analytics agent is definitely easier to deploy today. Keep in mind though, you are limited to your logging tiers. The agent is also end of life in a couple of years.
The Defender for Identity agent provides a different set of information. If you don’t have the requirement (or budget) to log actual events then it is still valuable. If you already use Defender for Identity and are starting to explore Sentinel, they are a good starting point. The cost will be significantly less than the other two agents. Also it does a lot of the hard work for you by doing its own event correlation.
You can also use multiple agents! Given the Azure Monitor agent is replacing the Log Analytics agent, they obviously perform similar functions. Unless you have very specific requirements you probably don’t need both of them. But you can definitely have one of them and the Defender for Identity agent running. You obviously pay the ingestion charges for both. But as we saw above, the Defender for Identity traffic is relatively small. If you go that route you get the logs for immediate detection and you also get the Defender for Identity insights.
The InfoSec community is amazing at providing insight into ransomware and malware attacks. There are so many fantastic contributors who share indicators of compromise (IOCs) and all kinds of other data. Community members and vendors publish detailed articles on various attacks that have occurred.
Usually these reports contain two different things. Indicators of compromise (IOCs) and tactics, techniques and procedures (TTPs). What is the difference?
Indicators of compromise – are some kind of evidence that an attack has occurred. This could be a malicious IP address or domain. It could be hashes of files. These indicators are often shared throughout the community. You can hunt for IOCs on places like Virus Total.
Tactics, techniques and procedures – describe the behaviour of how an attack occurred. These read more like a story of the attack. They are the ‘why’, the ‘what’ and the ‘how’ of an attack. Initial access was via phishing. Then reconnaissance. Then execution was via exploiting a scheduled task on a machine. These are also known as attack or kill chains. The idea being if you detected the attack earlier in the chain, the damage could have been prevented.
Using a threat intelligence source which provides IOCs is a key part to sound defence. If you detect known malicious files or domains in your environment then you need to react. There is, however, a delay between an attack occurring and these IOCs being available. Due to privacy, or legal requirements or dozens of other reasons, some IOCs may never be public. Also they can change. New malicious domains or IPs can come online. File hashes can change. That doesn’t make IOCs any less valuable. IOCs are still crucial and important in detection.
We just need to pair our IOC detection with TTP/kill chain detection to increase our defence. These kind of detections look for behaviour rather than specific IOCs. We want to try and detect suspicious activities, so that we can be alerted on potential attacks with no known IOCs. Hopefully these detections also occur earlier in the attack timeline and we are alerted before damage is done.
If we take for example the Trojan.Killdisk / HermeticWiper malware that has recently been documented. There are a couple of great write ups about the attack timeline. Symantec released this post which provides great insight. And Senior Microsoft Security Researcher Thomas Roccia (who you should absolutely follow) put together this really useful infographic. It visualizes the progression of the attack in a way that is easy to understand and follow. This visualizes both indicators and TTPs.
This article won’t focus on IOC detection, there are so many great resources for that. Instead we will work through the infographic and Symantec attack chain post. For each step in the chain, we will try to come up with a behavioural detection. Not one that focuses on any specific IOC, but to catch the activity itself. Using event logs and data taken from Microsoft Defender for Endpoint, we can generate some valuable alert rules.
From Thomas’ infographic we can see some early reconnaissance and defence evasion.
The attacker enumerated which privileges the account had. We can find these events with.
DeviceProcessEvents
| where FileName == "whoami.exe" and ProcessCommandLine contains "priv"
| project TimeGenerated, DeviceName, InitiatingProcessAccountName, FileName, InitiatingProcessCommandLine, ProcessCommandLine
We get a hit for someone looking at the privilege of the logged on account. This activity should not be occurring often in your environment outside of security staff.
The attacker then disabled the volume shadow copy service (VSS), to prevent restoration. When services are disabled they trigger Event ID 7040 in your system logs.
This query searches for the specific service disabled in this case. You could easily exclude the ‘ServiceName == “Volume Shadow Copy”‘ section. This would return you all services disabled. This may be an unusual event in your environment you wish to know about.
If we switch over to the Symantec article we can continue the timeline. So post compromise of a vulnerable Exchange server, the first activity noted is.
The decoded PowerShell was used to download a JPEG file from an internal server, on the victim’s network.
The article states they have decoded the PowerShell to make it readable for us. Which means it was encoded during the attack. Maybe our first rule could be searching for PowerShell that has been encoded? We can achieve that. Start with a broad query. Look for PowerShell and anything with an -enc or -encodedcommand switch.
DeviceProcessEvents
| where ProcessCommandLine contains "powershell" or InitiatingProcessCommandLine contains "powershell"
| where ProcessCommandLine contains "-enc" or ProcessCommandLine contains "-encodedcommand" or InitiatingProcessCommandLine contains "-enc" or InitiatingProcessCommandLine contains "-encodedcommand"
If you wanted to use some more advanced operators, we could extract the encoded string. Then attempt to decode it within our query. Query modified from this post.
DeviceProcessEvents
| where ProcessCommandLine contains "powershell" or InitiatingProcessCommandLine contains "powershell"
| where ProcessCommandLine contains "-enc" or ProcessCommandLine contains "-encodedcommand" or InitiatingProcessCommandLine contains "-enc" or InitiatingProcessCommandLine contains "-encodedcommand"
| extend EncodedCommand = extract(@'\s+([A-Za-z0-9+/]{20}\S+$)', 1, ProcessCommandLine)
| where EncodedCommand != ""
| extend DecodedCommand = base64_decode_tostring(EncodedCommand)
| where DecodedCommand != ""
| project TimeGenerated, DeviceName, InitiatingProcessAccountName, InitiatingProcessCommandLine, ProcessCommandLine, EncodedCommand, DecodedCommand
We can see a result where I encoded a PowerShell command to create a local account on this device.
We use regex to extract the encoded string. Then we use the base64_decode_tostring operator to decode it for us. This second query only returns results when the string can be decoded. So have a look at both queries and see the results in your environment.
This is a great example of hunting IOCs vs TTPs. We aren’t hunting for specific PowerShell commands. We are hunting for the behaviour of encoded PowerShell.
The next step was –
A minute later, the attackers created a scheduled task to execute a suspicious ‘postgresql.exe’ file, weekly on a Wednesday, specifically at 11:05 local-time. The attackers then ran this scheduled task to execute the task.
Attackers may lack privilege to launch an executable under system. They may have privilege to update or create a scheduled task running under a different user context. They could change it from a non malicious to malicious executable. In this example they have created a scheduled task with a malicious executable. Scheduled task creation is a specific event in Defender, so we can track those. We can also track changes and deletions of scheduled tasks.
There is a good chance you get significant false positives with this query. If you read on we will try to tackle that at the end.
Following from the scheduled task creation and execution, Symantec notes that next –
Beginning on February 22, Symantec observed the file ‘postgresql.exe’ being executed and used to perform the following
Execute certutil to check connectivity to trustsecpro[.]com and whatismyip[.]com Execute a PowerShell command to download another JPEG file from a compromised web server – confluence[.]novus[.]ua
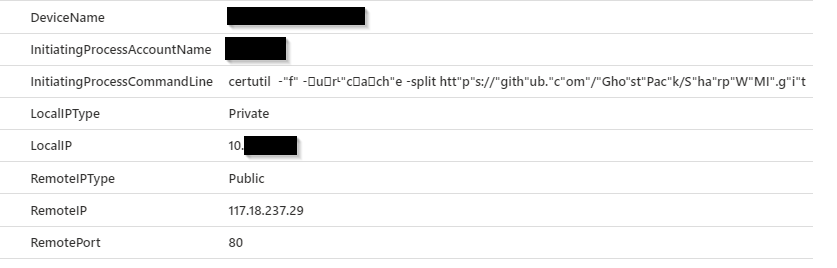
So the attackers leveraged certutil.exe to check internet connectivity. Certutil can be used to do this, and even download files. We can use our DeviceNetworkEvents table to find this kind of event.
We search for DeviceNetworkEvents where the initiating process command line includes certutil. We can also filter on only connections where the Remote IP is public if you have legitimate internal use.
We can see where I used certutil to download GhostPack from GitHub. I even attempted to obfuscate the command line, but we still found it. This is another great example of searching for TTPs. We don’t hunt for certutil.exe connecting to a specific IOC, but anytime it connects to the internet.
The next activity was credential dumping –
Following this activity, PowerShell was used to dump credentials from the compromised machine
There are many ways to dump credentials from a machine, many are outlined here. We can detect on procdump usage or comsvcs.dll exploitation. For comsvcs –
We can see as part of the running these scripts, the execution policy was changed. PowerShell execution bypass activity can be found easily enough.
DeviceProcessEvents
| where TimeGenerated > ago(1h)
| project InitiatingProcessAccountName, InitiatingProcessCommandLine
| where InitiatingProcessCommandLine has_all ("powershell","bypass")
This is another one that is going to be high volume. Let’s try and tackle that now.
With any queries that are relying on behaviour there is a chance for false positives. With false positives comes alert fatigue. We don’t want a legitimate alert buried in a mountain of noise. Hopefully the above queries don’t have any false positives in your environment. Unfortunately, that is not likely to be true. The nature of these attack techniques is they leverage tools that are used legitimately. We can try to tune these alerts down by whitelisting particular servers or commands. We don’t want to whitelist the server that is compromised.
Instead, we could look at adding some more intelligence to our queries. To do that we can try to add a baseline to our environment. Then we alert when something new occurs.
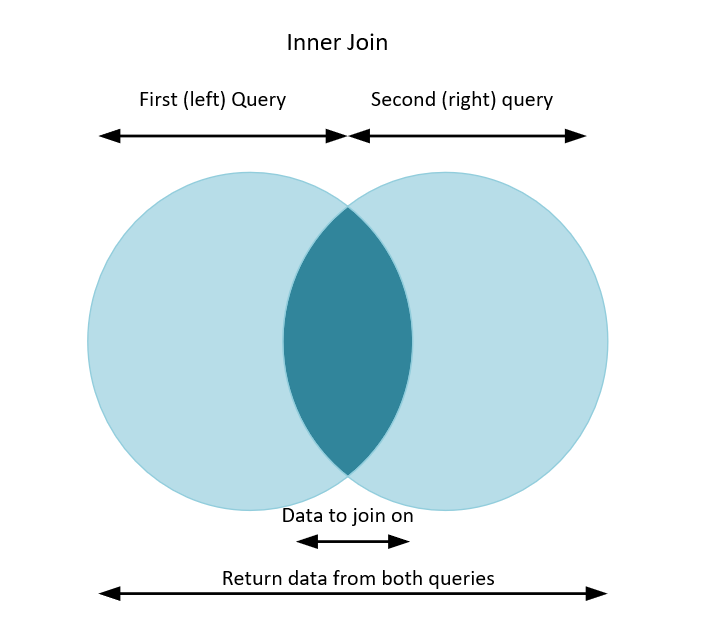
We build these types of queries by using an anti join in KQL. Anti joins can be a little confusing, so let’s try to visualize them from a security point of view.
First, think of a regular (or inner) join in KQL. We take two queries or tables and join them together on a field (or fields) that exist in both tables. Maybe you have firewall data and Active Directory data. Both have IP address information so you can join them together. Have a read here for an introduction to inner joins. We can visualize an inner join like this.
So for a regular (or inner) join, we write two queries, then match them on something that is the same in both. Maybe an IP address, or a username. Once we join we can retrieve information back from both tables.
When we expand on this, we can do anti-joins. Let’s visualize a leftanti join.
So we can again write two queries, join them on a matching field. But this time, we only return data from the first (left) query. A rightanti join is the opposite.
For rightanti joins we run our two queries. We match on our data. But this time we only return results that exist in the second (or right) query.
With joins in KQL, you don’t need to join between two different data sets. Which can be confusing to grasp. You can join between the same table, with different query options. So we can query the DeviceEvent table for one set of data. Query the DeviceEvent table again, with different parameters. Then join them in different ways. When joining the same table together I think of it like this –
Use a leftanti join when you want to detect when something stops happening.
Use a rightanti join when you want to detect when something happens for the first time.
Now let’s see how we apply these joins to our detection rules.
Scheduled task creation is a good one to use as an example. Chances are you have legitimate software on your devices that create tasks. We will use our rightanti join to add some intelligence to our query.
Let’s look at the following query.
DeviceEvents
| where TimeGenerated > ago(30d) and TimeGenerated < ago(1h)
| where ActionType == "ScheduledTaskCreated"
| extend ScheduledTaskName = tostring(AdditionalFields.TaskName)
| distinct ScheduledTaskName
| join kind=rightanti
(DeviceEvents
| where TimeGenerated > ago(1h)
| where ActionType == "ScheduledTaskCreated"
| extend ScheduledTaskName = tostring(AdditionalFields.TaskName)
| project TimeGenerated, DeviceName, ScheduledTaskName, InitiatingProcessAccountName)
on ScheduledTaskName
| project TimeGenerated, DeviceName, InitiatingProcessAccountName, ScheduledTaskName
Our first (or left) query looks at our DeviceEvents. We go back between 30 days ago and one hour ago. From that data, all we care about are the names of all the scheduled tasks that have been created. So we use the distinct operator. That first query becomes our baseline for our environment.
Next we select our join type. Kind = rightanti. We join back to the same table, DeviceEvents. This time though, we are only interested in the last hour of data. We retrieve the TimeGenerated, DeviceName, InitiatingProcessAccountName and ScheduledTaskName.
Then we tell KQL what field we want to join on. We want to join on ScheduledTaskName. Then return only data that is new in the last hour.
So to recap. First find all the scheduled tasks created between 30 days and an hour ago. Then find me all the scheduled tasks created in the last hour. Finally, only retrieve tasks that are new to our environment in the last hour. That is how we do a rightanti join.
Another example is PowerShell commands that change the execution policy to bypass. You probably see plenty of these in your environment
DeviceProcessEvents
| where TimeGenerated > ago(30d) and TimeGenerated < ago(1h)
| project InitiatingProcessAccountName, InitiatingProcessCommandLine
| where InitiatingProcessCommandLine has_all ("powershell","bypass")
| distinct InitiatingProcessAccountName, InitiatingProcessCommandLine
| join kind=rightanti (
DeviceProcessEvents
| where TimeGenerated > ago(1h)
| project
TimeGenerated,
DeviceName,
InitiatingProcessAccountName,
InitiatingProcessCommandLine
| where InitiatingProcessAccountName !in ("system","local service","network service")
| where InitiatingProcessCommandLine has_all ("powershell","bypass")
)
on InitiatingProcessAccountName, InitiatingProcessCommandLine
This query is nearly the same as the one previous. We look back between 30 days and one hour. This time we query for commands executed that contain both ‘powershell’ and ‘bypass’. This time we retrieve both distinct commands and the account that executed them.
Then choose our rightanti join again. Run the same query once more for the last hour. We join on both our fields. Then return what is new to our environment in the last hour. For this query, the combination of command line and account needs to be unique.
For this particular example I excluded processes initiated by system, local service or network service. This will find events run under named user accounts only. This is an example though and it is easy enough to include all commands.
In summary.
These queries aren’t meant to be perfect hunting queries for all malware attack paths. They may definitely useful detections in your environment though. The idea is to try to help you think about TTP detections.
When you read malware and ransomware reports you should look at both IOCs and TTPs.
Detect on the IOCs. If you use Sentinel you can use Microsoft provided threat intelligence. You can also include your own feeds. Information is available here. There are many ready to go rules to leverage that data you can simply enable.
For TTPs, have a read of the report and try to come up with queries that detect that behaviour. Then have a look how common that activity is for you. The example above of using certutil.exe to download files is a good example. That may be extremely rare in your environment. Your hunting query doesn’t need to list the specific IOCs to that action. You can just alert any time certutil.exe connects to the internet.
Tools like PowerShell are used both maliciously and legitimately. Try to write queries that detect changes or anomalies in those events. Apply your knowledge of your environment to try and filter the noise without filtering out genuine alerts.
All the queries in this post that use Device* tables should also work in Advanced Hunting. You will just need to change ‘timegenerated’ to ‘timestamp’.
For people that use a lot of cloud workloads you would know it can be hard to track cost. Billing in the cloud can be volatile if you don’t keep on top of it. Bill shock is a real thing. While large cloud providers can provide granular billing information. It can still be difficult to track spend.
The unique thing about Sentinel is that it is a huge datastore of great information. That lets us write all kinds of queries against that data. We don’t need a third party cost management product, we have all the data ourselves. All we need to know is where to look.
It isn’t all about cost either. We can also also detect changes to data. Such as finding new information that can be helpful, or detect when data isn’t received.
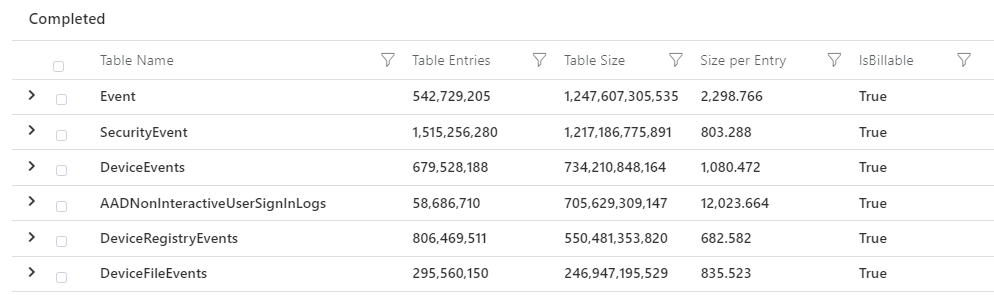
Start by listing all your tables and the size of them over the last 30 days. Query adapted from this one.
union withsource=TableName1 *
| where TimeGenerated > ago(30d)
| summarize Entries = count(), Size = sum(_BilledSize) by TableName1, _IsBillable
| project ['Table Name'] = TableName1, ['Table Entries'] = Entries, ['Table Size'] = Size,
['Size per Entry'] = 1.0 * Size / Entries, ['IsBillable'] = _IsBillable
| order by ['Table Size'] desc
You will get an output of the table size for each table you have in your workspace. We can even see if it is free data or billable.
Now table size by itself may not have enough context for you. So to take it further, we can compare time periods. Say we want to view table size last week vs this week. We do that with the following query.
let lastweek=
union withsource=_TableName *
| where TimeGenerated > ago(14d) and TimeGenerated < ago(7d)
| summarize
Entries = count(), Size = sum(_BilledSize) by Type
| project ['Table Name'] = Type, ['Last Week Table Size'] = Size, ['Last Week Table Entries'] = Entries, ['Last Week Size per Entry'] = 1.0 * Size / Entries
| order by ['Table Name'] desc;
let thisweek=
union withsource=_TableName *
| where TimeGenerated > ago(7d)
| summarize
Entries = count(), Size = sum(_BilledSize) by Type
| project ['Table Name'] = Type, ['This Week Table Size'] = Size, ['This Week Table Entries'] = Entries, ['This Week Size per Entry'] = 1.0 * Size / Entries
| order by ['Table Name'] desc;
lastweek
| join kind=inner thisweek on ['Table Name']
| extend PercentageChange=todouble(['This Week Table Size']) * 100 / todouble(['Last Week Table Size'])
| project ['Table Name'], ['Last Week Table Size'], ['This Week Table Size'], PercentageChange
| sort by PercentageChange desc
We run the same query twice, over our two time periods. Then join them together based on the name of the table. So we have our table, last weeks data size, then this weeks data size. Then, to make it even easier to read, we calculate the percentage change in size.
You could use this data and query to create an alert when tables increase or decrease in size. To reduce noise you can even filter on table size or percentage change. You could add the following to the query to achieve that. A small table may increase in size by 500% but is still small.
| where ['This Week Table Size'] > 1000000 and PercentageChange > 1.10
Of course, it wouldn’t be KQL if you couldn’t visualize your log source data too. You could provide a summary of your top 15 log sources with.
union withsource=_TableName *
| where TimeGenerated > ago(30d)
| summarize LogCount=count()by Type
| sort by LogCount desc
| take 15
| render piechart with (title="Top 15 Log Sources")
You could go to an even higher level, and look for new data sources or tables not seen before. To find things that are new in our data, we use the join operator, using a rightanti join. Rightanti joins say, show me results from the second query (the right) that weren’t in the first (the left). The following query will return new tables from the last week, not seen for the prior 90 days.
union withsource=_TableName *
| where TimeGenerated > ago(90d) and TimeGenerated < ago(7d)
| distinct Type
| project-rename ['Table Name']=Type
| join kind=rightanti
(
union withsource=_TableName *
| where TimeGenerated > ago(7d)
| distinct Type
| project-rename ['Table Name']=Type )
on ['Table Name']
Let’s have a closer look at that query to break it down. Joining queries in KQL is the most challenging aspect to learn.
We run the first query (our left query), which finds all the table names from between 90 and 7 days ago. Then we choose our join type, in this case rightanti. Then we run the second query, which finds all the tables from the last 7 days. Then finally we choose what field we want to join the table on, in this case, Table Name. We tell KQL to only display items from the right (the second query), that don’t appear in the left (first query). So only show me table names that have appeared in the last 7 days, that didn’t appear in the 90 days before. When we run it, we get our results.
We can flip this around too. We can find tables that have stopped sending data in the last 7 days too. Keep the same query and change the join type to leftanti. Now we retrieve results from our first query, that no longer appear in our second.
union withsource=_TableName *
| where TimeGenerated > ago(90d) and TimeGenerated < ago(7d)
| distinct Type
| project-rename ['Table Name']=Type
| join kind=leftanti
(
union withsource=_TableName *
| where TimeGenerated > ago(7d)
| distinct Type
| project-rename ['Table Name']=Type )
on ['Table Name']
Logs not showing up? It could be expected if you have offboarded a resource. Or you may need to investigate why data isn’t arriving. In fact, we can use KQL to calculate the last time a log arrived for each table in our workspace. We grab the most recent record using the max() operator. Then we calculate how many days ago that was using datetime_diff.
union withsource=_TableName *
| where TimeGenerated > ago(90d)
| summarize ['Days Since Last Log Received'] = datetime_diff("day", now(), max(TimeGenerated)) by _TableName
| sort by ['Days Since Last Log Received'] asc
Let’s go further. KQL has inbuilt forecasting ability. You can query historical data then have it forecast forward for you. This example looks at the prior 30 days, in 12 hour blocks. It then forecasts the next 7 days for you.
union withsource=_TableName *
| make-series ["Total Logs Received"]=count() on TimeGenerated from ago(30d) to now() + 7d step 12h
| extend ["Total Logs Forecast"] = series_decompose_forecast(['Total Logs Received'], toint(7d / 12h))
| render timechart
It doesn’t need to be all about cost either. We can use similar queries to alert on things that are new we may otherwise miss. Take for instance the SecurityAlerts table. Microsoft security products like Defender or Azure AD protection write alerts here. Microsoft are always adding new detections which are hard to keep on top of. We can use KQL to detect alerts that are new to our environment we have never seen before.
SecurityAlert
| where TimeGenerated > ago(180d) and TimeGenerated < ago(7d)
// Exclude alerts from Sentinel itself
| where ProviderName != "ASI Scheduled Alerts"
| distinct AlertName
| join kind=rightanti (
SecurityAlert
| where TimeGenerated > ago(7d)
| where ProviderName != "ASI Scheduled Alerts"
| summarize NewAlertCount=count()by AlertName, ProviderName, ProductName)
on AlertName
| sort by NewAlertCount desc
When we run this, any new alerts from the last week not seen prior are visible. To add some more context, we also count how many times we have had the alerts in the last week. We also bring back which product triggered the alert.
Microsoft and others add new detections so often it’s impossible to keep track of. Let KQL to the work for you. We can use similar queries across other data. Such as OfficeActivity (your Office 365 audit traffic).
OfficeActivity
| where TimeGenerated > ago(180d) and TimeGenerated < ago(7d)
| distinct Operation
| join kind=rightanti (
OfficeActivity
| where TimeGenerated > ago(7d)
| summarize NewOfficeOperations=count()by Operation, OfficeWorkload)
on Operation
| sort by NewOfficeOperations desc
For OfficeActivity we can bring back the Office workload so we know where to start looking.
Or Azure AD audit data.
AuditLogs
| where TimeGenerated > ago(180d) and TimeGenerated < ago(7d)
| distinct OperationName
| join kind=rightanti (
AuditLogs
| where TimeGenerated > ago(7d)
| summarize NewAzureADAuditOperations=count()by OperationName, Category)
on OperationName
| sort by NewAzureADAuditOperations desc
For Azure AD audit data we can also return the category for some context.
I hope you have picked up some tricks on how to use KQL to provide insights into your data. You can query your own data the same way you would hunt threats. By looking for changes to log volume, or new data that could be interesting.
There are also some great workbooks provided by Microsoft and the community. These visualize a lot of similar queries for you. You should definitely check them out in your tenant.
Defenders spend a lot of time worrying about the security of the user identities they manage. Trying to stop phishing attempts or deploying MFA. You want to restrict privilege, have good passphrase policies and deploy passwordless solutions. If you use Azure AD, there is another type of identity that is important to keep an eye on – Azure AD service principals.
There is an overview of service principals here. Think about your regular user account. When you want to access Office 365, you have a user principal in Azure AD. You give that user access, to SharePoint, Outlook and Teams, and when you sign in you get that access. Your applications are the same. They have a principal in Azure AD, called a service principal. These define what your applications can access.
You haven’t seen anywhere in the Azure AD portal a ‘create service principal’ button. Because there isn’t one. Yet you likely have plenty of service principals already in your tenant. So how do they get there? Well, in several ways.
So if we complete any of the following actions, we will end up with a service principal –
Add an application registration – each time you register an application. For example to enable SSO for an application you are developing. Or to integrate with Microsoft Graph. You will end up with both an application object and an service principal in your tenant.
Install a third party OAuth application – if you install an app to your tenant. For instance an application in Microsoft Teams. You will have a service principal created for it.
Install a template SAML application from the gallery – when you setup SSO with a third party SaaS product. If you deploy their gallery application to help. Both an application object and a service principal in your tenant.
Add a managed identity – each time you create a managed identity, you also create a service principal.
You may also have legacy service principals. Created before the current app registration process existed.
If you browse to Azure AD -> Enterprise applications, you can view them all. Are all these service principals a problem? Not at all, it is the way that Azure Active Directory works. It uses service principals to define access and permissions for applications. Service principals are in a lot of ways much more secure than alternatives. Take a service principal for a managed identity – it can end the need for developers to use credentials. If you want an Azure virtual machine to access to an Azure Key Vault, you can create a managed identity. This also creates a service principal in Azure AD. Then assign the service principal access to your key vault. Your virtual machine then identifies itself to the key vault. The key vault says ‘hey I know this service principal has access to this key vault’ and gives it access. Much better than handling passwords and credentials in code.
In the case of a system assigned managed identity, the lifecycle of the service principal is also managed. If you create a managed identity for a Azure virtual machine then decommission the virtual machine. The service principal, and any access it has, is also removed.
Like any identity, we can grant service principals excess privilege. You could make a service account in on premise Active Directory a domain admin, you shouldn’t, but you can. Service principals are the same, we can assign all kinds of privilege in Azure AD and to Azure resources. So how can service principals get privilege, and what kind of privilege can they have? We can build on our visualization of we created service principals. Now we add how they gain privilege.
So much like users, we can assign various access to service principals, such as –
Assigned an Azure AD to role – if we add them to roles such as global or application administrator.
Granted access to the Microsoft Graph or other Microsoft API – if we add permissions like Directory.ReadWrite.All or Policy.ReadWrite.ConditionalAccess from Microsoft Graph. Or other API access like Defender ATP or Dynamics 365, or your own APIs.
Granted access to Azure RBAC – if we add access such as owner rights to a subscription or contributor to a resource group.
Given access to specific Azure workloads – such as being able to read secrets from an Azure Key Vault.
Service principals having privilege is not an issue, in fact, they need to have privilege. If we want to be able to SSO users to Azure AD then the service principal needs that access. Or if we want to automate retrieving emails from a shared mailbox then we will need to provide that access. Like users, we can assign incorrect or excessive privilege which is then open to abuse. Explore the abuse of service principals by checking the following article from @DebugPrivilege. It shows how you can use the managed identity of a virtual machine to retrieve secrets from a key vault.
We can get visibility into any of these changes in Microsoft Sentinel. When we grant a service principal access to Azure AD or to Microsoft Graph, we use the Azure AD Audit log. Which we access via the AuditLogs table in Sentinel. For changes to Azure RBAC and specific Azure resources, we use the AzureActivity or AzureDiagnostics table.
You can add Azure AD Audit Logs to your Sentinel instance. You do this via the Azure Active Directory connector under data connectors. This is a very useful table but ingestion fees will apply.
For the sake of this blog, I have created a service principal called ‘Learn Sentinel’. I used the app registration portal in Azure AD. We will now give privilege to that service principal and then detect in Sentinel.
Adding Azure Active Directory Roles to a Service Principal
If we work through our list of how a service principal can gain privilege we will start with adding an Azure AD role. I have added the ‘Application Administrator’ role to my service principal using PowerShell. We can run the cmdlet below. Where ObjectId is the Id of the role, and RefObjectId is the Object Id of the service principal. You can get all the Ids of all the roles by first running Get-AzureADDirectoryRole first.
We track this activity under the action ‘Add member to role’ in our Audit Log. Which is the same action you see when we add a regular user account to a role. There is a field, nested in the TargetResources data, that we can leverage to ensure our query only returns service principals –
If we complete our query, we can filter for only events where the type is “ServicePrincipal”
If we run our query we see the activity with the details we need. When the event occurred, what role, to which service principal, and who did it.
Everyone uses Azure AD in different ways, but this should not be a very common event in most tenants. Especially with high privilege roles such as Application, Privileged Authentication or Global Administrator. You should alert on any of these events. To see how you could abuse the Application Administrator role, check out this blog post from @_wald0. It shows how you can leverage that role to escalate privilege.
Adding Microsoft Graph (or other API) access to a Service Principal
If you create service principals for integration with other Microsoft services like Azure AD or Office 365 you will need to add access to make it work. It is common for third party applications, or those you are developing in house, to request access. It is important to only grant the access required.
For this example I have added
Policy.ReadWrite.ConditionalAccess (ability to read & write conditional access policies)
User.Read.All (read users full profiles)
to our same service principal.
When we add Microsoft Graph access to an app, the Azure AD Audit Log tracks the event as “Add app role assignment to service principal”. We can parse out the relevant information we want in our query to return the specifics. You can use this as the completed query to find these events, including the user that did it.
AuditLogs
| where OperationName == "Add app role assignment to service principal"
| extend AppRoleAdded = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[1].newValue)))
| extend ActorIPAddress = tostring(parse_json(tostring(InitiatedBy.user)).ipAddress)
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend ServicePrincipalObjectId = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[3].newValue)))
| extend ServicePrincipalName = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[4].newValue)))
| project TimeGenerated, OperationName, AppRoleAdded, ServicePrincipalName, ServicePrincipalObjectId,Actor, ActorIPAddress
When we run our query we see the events, even though I added both permissions together, we get two events.
Depending on how often you create service principals in your tenant, and who can grant access I would alert on all these events to ensure that service principals are not granted excessive privilege. This query also covers other Microsoft APIs such as Dynamics or Defender, and your own personal APIs you protect with Azure AD.
Adding Azure access to a Service Principal
We can grant service principals access to high level management scopes in Azure, such as subscriptions or resource groups. For instance, if you had an asset management system that you used to track your assets in Azure. It could use Azure AD for authentication and authorization. You would create a service principal for your asset management system, then give it read access your subscriptions. The asset management application could then view all your assets in those subscriptions. We track these kind of access changes in the AzureActivity log. This is a free table so you should definitely ingest it.
For this example I have added our service principal as a contributor on a subscription and a reader on a resource group.
The AzureActivity log can be quite verbose and the structure of the logs changes often. For permissions changes we are after the OperationNameValue of “MICROSOFT.AUTHORIZATION/ROLEASSIGNMENTS/WRITE”. When we look at the structure of some of the logs, we can see that we can filter on service principals. As opposed to granting users access.
We can use this query to search for all events where a service principal was given access.
We see our two events. The first when I added a service principal to the subscription, then second to a resource group. You can see the target under ‘Scope’.
You will notice a couple of things. The name of role assigned (in this example, contributor and reader) isn’t returned. Instead we see the role id (the final section of the RoleAdded field). You can find the list of mappings here. We are also only returned the object id of our service principal, not the friendly name. Unfortunately the friendly name isn’t contained within the logs, but this still alerts us to investigate.
When you assign access to subscription or resource group, you may notice you have an option. Either a user, group or service principal or a managed identity.
The above query will find any events for service principals or managed identities. You won’t need a specific one for managed identities.
Adding Azure workload access to a Service Principal
We can also grant our service principals access to Azure workloads. Take for instance being able to read or write secrets into an Azure Key Vault. We will use that as our example below. I have given our service principal the ability to read and list secrets from a key vault.
We track this in the AzureDiagnostics table for Azure Key Vault. We can use the following query to track key vault changes.
AzureDiagnostics
| where ResourceType == "VAULTS"
| where OperationName == "VaultPatch"
| where ResultType == "Success"
| project-rename ServicePrincipalAdded=addedAccessPolicy_ObjectId_g, Actor=identity_claim_http_schemas_xmlsoap_org_ws_2005_05_identity_claims_name_s, AddedKeyPolicy = addedAccessPolicy_Permissions_keys_s, AddedSecretPolicy = addedAccessPolicy_Permissions_secrets_s,AddedCertPolicy = addedAccessPolicy_Permissions_certificates_s
| where isnotempty(AddedKeyPolicy) or isnotempty(AddedSecretPolicy) or isnotempty(AddedCertPolicy)
| project TimeGenerated, KeyVaultName=Resource, ServicePrincipalAdded, Actor, IPAddressofActor=CallerIPAddress, AddedSecretPolicy, AddedKeyPolicy, AddedCertPolicy
We find the service principal Id that we added, the key vault permissions added, the name of the vault and who did it.
We could add a service principal to many Azure resources. Azure Storage, Key Vault, SQL, are a few, but similar events should be available for them all.
Azure AD Service Principal Sign In Data
As well as audit data to track access changes, we can also view the sign in information for service principals and managed identities. Microsoft Sentinel logs these two types of sign ins in two separate tables. For regular service principals we query the AADServicePrincipalSignInLogs. For managed identity sign in data we look in AADManagedIdentitySignInLogs. You can enable both logs in the Azure Active Directory data connector. These should be low volume compared to regular sign in data but fees will apply.
Service principals sign in logs aren’t as detailed as your regular user sign in data. These types of sign ins are non interactive and are instead accessing resources protected by Azure AD. There are no fields for things like multifactor authentication or anything like that. This makes the data easy to make sense of. If we look at a sign in for our test service principal, you will see the information you have available to you.
We can see we get some great information. There are other fields available but for the sake of brevity I will only show a few.
We get a ResultType, much like a regular user sign in (0 = success). The IP address, the name of the service principal, then the Id’s of pretty much everything. Even the resource the service principal was accessing. We can summarize our data to see patterns for all our service principals. For instance, by listing all the IP addresses each service principal has signed in from in the last month.
AADServicePrincipalSignInLogs
| where TimeGenerated > ago(30d)
| where ResultType == "0"
| summarize IPAddresses=make_set(IPAddress) by ServicePrincipalName, AppId
Conditional Access for workload identities was recently released for Azure AD. If your service principals log in from the same IP addresses then enforce that with conditional access. That way, if we lose client secrets or certificates, and an attacker signs in from a new IP address we will block it. Much like conditional access for users. The above query will give you your baseline of IP addresses to start building policies.
We can also summarize the resources that each service principal has accessed. If you have service principals that can access many resources such as Microsoft Graph, the Windows Defender ATP API and Azure Service Management API. Those service principals likely have a larger blast radius if compromised –
AADServicePrincipalSignInLogs
| where TimeGenerated > ago(30d)
| where ResultType == "0"
| summarize ResourcesAccessed=make_set(ResourceDisplayName) by ServicePrincipalName
We can use similar detection patterns we would use for users with service principals. For instance detecting when they sign in from a new IP address not seen for that service principal. This query alerts when a service principal signs in to a new IP address in the last week compared to the prior 180 days.
let timeframe = 180d;
AADServicePrincipalSignInLogs
| where TimeGenerated > ago(timeframe) and TimeGenerated < ago(7d)
| distinct AppId, IPAddress
| join kind=rightanti
(
AADServicePrincipalSignInLogs
| where TimeGenerated > ago(7d)
| project TimeGenerated, AppId, IPAddress, ResultType, ServicePrincipalName
)
on IPAddress
| where ResultType == "0"
| distinct ServicePrincipalName, AppId, IPAddress
For managed identities we get a cut down version of the service principal sign in data. For instance we don’t get IP address information because managed identities are used ‘internally’ within Azure AD. But we can still track them in similar ways. For instance we can summarize all the resources each managed identity accesses. For instance Azure Key Vault, Azure Storage, Azure SQL. The higher the count, then the higher the blast radius.
AADManagedIdentitySignInLogs
| where TimeGenerated > ago(30d)
| where ResultType == 0
| summarize ResourcesAccessed=make_set(ResourceDisplayName) by ServicePrincipalName
We can also detect when a managed identity accesses a new resource that it hadn’t before. This query will return any managed identities that access resources that they hadn’t in the prior 60 days. For example, if you have a managed identity that previously only accessed Azure Storage, then accesses an Azure Key Vault, this would find that event.
AADManagedIdentitySignInLogs
| where TimeGenerated > ago (60d) and TimeGenerated < ago(1d)
| where ResultType == "0"
| distinct ServicePrincipalId, ResourceIdentity
| join kind=rightanti (
AADManagedIdentitySignInLogs
| where TimeGenerated > ago (1d)
| where ResultType == "0"
)
on ServicePrincipalId, ResourceIdentity
| distinct ServicePrincipalId, ServicePrincipalName, ResourceIdentity, ResourceDisplayName
Prevention, always better than detection.
As with anything, preventing issues is better than detecting them. The nature of service principals though is they are always going to have some privilege. It is about reducing risk in your environment through least privilege.
Get to know your Azure AD roles and Microsoft Graph permisions. Assign only what you need. Avoid using roles like Global Administrator and Application Adminstrator. Limit permissions such as Directory.Read.All and Directory.ReadWrite. All are high privilege and should not be required. Azure AD roles can also be scoped to reduce privilege to only what is required.
Alert when service principals are assigned roles in Azure AD or granted access to Microsoft Graph using the queries above. Investigate whether the permissions are appropriate to the workload.
Make sure that any access granted to Azure management scopes or workloads is fit for purpose. Owner, contributor and user access administrator are all very high privilege.
Leverage Azure AD Conditional Access for workload identities. If your service principals sign in from a known set of IP addresses, then enforce that in policy.
Don’t be afraid to push back on third parties or internal developers about the privilege required to make their application work. The Azure AD and Microsoft Graph documentation is easy to read and understand and the permissions are very granular.
Finally, some handy links from within this article and elsewhere
Functions in Microsoft Sentinel are an overlooked and underappreciated feature in my experience, there is no specific Sentinel guidance provided by Microsoft on how to use them, however they are covered more broadly under the Azure Monitor section of the Microsoft docs site. In general terms though, they allow us to save queries to our Sentinel workspace, then invoke them by a simple name. So imagine you have written a really great query that looks for Active Directory group changes from Security Event logs, and your query also parses the data to make it look tidy and readable. Instead of having to re-use that same query over and over, you can save it to your workspace as a function, and then simply refer to it when needed.
We are going to use the example of Active Directory group membership changes to show how you can speed up your queries using functions. So first up we need to write our query, for anyone that has spent time looking at Security Event logs, the data can be a little inconsistent, and we sometimes need to parse the information we want from a large string of text. We also get a lot of information we just may not care about. Perhaps we only care about what time the event occurred, who was added or removed from the group, the group name and who was the person that made the changes.
To do that we can use the following query –
SecurityEvent
| project TimeGenerated, EventID, AccountType, MemberName, SubjectUserName, TargetUserName, Activity, MemberSid
| where EventID in (4728,4729,4732,4733,4756,4757)
| where AccountType == "User"
| parse MemberName with * 'CN=' UserAdded ',OU=' *
| project TimeGenerated, UserWhoAdded=SubjectUserName, UserAdded, GroupName=TargetUserName, Activity
Now we get a nice sanitized output that is easy to read showing the data we care about.
Now we are happy with our query, let’s save it as a function so we can refer it to it easily. Above your query you can see ‘Save’, if you click on that you will see an option for ‘Save as function’
Choose a name for your function, what you call it here is what you will use to then invoke it, you also choose a Legacy category to help categorize your functions.
So for this example we will call it ‘ADGroupChanges’, it will show you the code it is saving underneath, then hit Save. Give it a couple of minutes to become available to your workspace. When you start to type the name in your query window, you will notice it will now list the function as available to you. The little 3d rectangle icon highlights it as a function.
You can just run that ADGroupChanges on its own with no other input and it will simply run the saved code for you, and retrieve all the Active Directory group changes. Where you get real power from functions though is that you can continue to use your normal Kusto skills and operators against the function. You aren’t bound by only what is referenced in the function code. So you can do things like time limit your query to the last hour.
ADGroupChanges
| where TimeGenerated > ago(1h)
This applies our function code then only retrieves the last hour of results. You can include all your great filtering operators like has and in. The below will search for changes in the last hour and also where the name of the group has “Sentinel” in it.
ADGroupChanges
| where TimeGenerated > ago(1h)
| where GroupName has "Sentinel"
Or if you are looking for actions from a particular admin you can search on the UserWhoAdded field.
ADGroupChanges
| where TimeGenerated > ago(1h)
| where UserWhoAdded has "admin123"
Of course you can do combinations of any of these. Such as finding any groups that admin123 added testuser123 to in the last 24 hours.
ADGroupChanges
| where TimeGenerated > ago(24h)
| where UserWhoAdded has "admin123" and UserAdded has "testuser123"
If you ever want to check out what the query is under the function, just browse to ‘Functions’ on your workspace and they are listed under ‘Workspace functions’
If you hover over your function name, you will get a pop up appear, just select ‘Load the function code’ and it will load it into your query window for you.
If you want to update your function, just edit your query then save it again with the same name. That is what we are going to do now, by adding some more information to our query from our IdentityInfo table. Our Security Event log contains really only the basics of what we want to know, but maybe we want to enrich that with some better identity information. So if we update our query to the below, where we join our UserAdded field to our IdentityInfo table, we can then retrieve information from both, such as department, manager, and location details.
SecurityEvent
| project TimeGenerated, EventID, AccountType, MemberName, SubjectUserName, TargetUserName, Activity, MemberSid
| where EventID in (4728,4729,4732,4733,4756,4757)
| where AccountType == "User"
| parse MemberName with * 'CN=' UserAdded ',OU=' *
| project TimeGenerated, UserWhoAdded=SubjectUserName, UserAdded, UserAddedSid=MemberSid, GroupName=TargetUserName, Activity
| join kind=inner(
IdentityInfo
| where TimeGenerated > ago (21d)
| summarize arg_max(TimeGenerated, *) by AccountUPN)
on $left.UserAdded==$right.AccountName
| project TimeGenerated, UserWhoAdded, UserWhoAddedUPN=AccountUPN, GroupName, Activity, UserAdded, EmployeeId, City, Manager, Department
Save over your function with that new code. Now we have the information from our Security Event table showing when changes occurred, plus our great identity information from our IdentityInfo table. We can use that to write some queries that wouldn’t otherwise be available to us because our Security Event logs simply don’t contain that information.
Looking for group changes from users within a particular department? We can query on that.
ADGroupChanges
| where TimeGenerated > ago(24h)
| where Department contains "IT Service Desk"
You can combine your queries to take information from both the tables we joined in our function, say you are interested in querying for changes to a particular group name where the users are in a particular location, we can now do that having built our function.
ADGroupChanges
| where TimeGenerated > ago(250m)
| where GroupName == "testgroup123" and City contains "Seattle"
This will find changes to ‘testgroup123’ where the user added is from Seattle. Under the hood we look up group name from our Security Event table and City from our IdentityInfo table.
Functions are also really useful if you are trying to get other team members up to speed with Sentinel or KQL. Instead of needing them to do the parsing or data clean up in their own queries, you can build a function for them and have them stick to easier to understand operators like contains or has as a stepping stone to building out their skill set. KQL is a really intuitive language but it can still be daunting to people who haven’t seen it before. They are also a great way for you to just save time yourself, if you have spent ages building really great queries and parsers then just save them for future use, rather than trying to remember what you did previously. The ‘raw’ data will always be there if you want to go back and look at it, the function is just doing the hard work for us.
If you want a few more examples I have listed them here – they include a function to retrieve Azure Key Vault access changes, to find all your domain controllers via various log sources, and a function to join identity info with both sign in logs and risk events.
Azure AD External Identities (previously Azure AD B2B) is a fantastic way to collaborate with partners, customers or other people external to your company. Previously you may have needed to onboard an Active Directory account for each user, which came with a lot of inherit privilege, or you used different authentication methods for your applications, and you ended up juggling credentials for all these different systems. By leveraging Azure AD External Identities you start to wrestle back some of that control and importantly get really strong visibility into what these guests are doing.
You invite a guest to your tenant by sending them an email from within the Azure Active Directory portal (or directly inviting them in an app like Teams), they go through the process of accepting and then you have a user account for them in your tenant – easy!
If the user you invite to your tenant belongs to a domain that is also an Azure AD tenant, they can use their own credentials from that tenant to access resources in your tenant. If it’s a personal address like gmail.com then the user will be prompted to sign up to a Microsoft account or use a one time passcode if you have configured that option.
If you browse through your Azure AD environment and already have guests, you can filter to just guest accounts. If you don’t have guests, invite your personal email and you can check out the process.
You will notice that they have a unique UserPrincipalName format, if your guests email address is test123@gmail.com then the guest object in your directory has the UserPrincipalName of test123_gmail.com#EXT#@YOURTENANT.onmicrosoft.com – this makes sense if you think about the concept of a guest account, it could belong to many different tenants so it needs to have a unique UPN in your tenant. You can also see a few more details by clicking through to a guest account. You can see if an invite has been accepted or not, a guest who hasn’t accepted is still an object in your directory, they just can’t access any resources yet.
And if you click the view more arrow, you can see if source of the account.
You can see the difference between a user coming in from another Azure AD tenant vs a personal account.
It is really easy to invite guest accounts and then kind of forget about them, or not treat them with the same scrutiny or governance you would a regular account. They also have a tendency to grow in total count very quickly, especially if you allow your staff to invite them themselves, via Teams or any other method.
Remember though these accounts all have some access to your tenant, potentially data in Teams, OneDrive or SharePoint, and likely an app or two that you have granted access to – or more worryingly apps that you haven’t specifically blocked them accessing. Guests can even be granted access to Azure AD roles, or be given access to Azure resources via Azure RBAC.
Thankfully in Microsoft (no longer Azure!) Sentinel, all the signals we get from sign-in data, or audit logs, or Office 365 logs don’t discriminate between members and guests (apart from some personal information that is hidden for guests such as device names), which makes it a really great platform to get insights to what your guests are up to (or what they are no longer up to).
Invites sent and redeemed are collected in the AuditLogs table, so if you want to quickly visualize how many invites you are sending vs those being redeemed you can.
//Visualizes the total amount of guest invites sent to those redeemed
let timerange=180d;
let timeframe=7d;
AuditLogs
| where TimeGenerated > ago (timerange)
| where OperationName in ("Redeem external user invite", "Invite external user")
| summarize
InvitesSent=countif(OperationName == "Invite external user"),
InvitesRedeemed=countif(OperationName == "Redeem external user invite")
by bin(TimeGenerated, timeframe)
| render columnchart
with (
title="Guest Invites Sent v Guest Invites Redeemed",
xtitle="Invites",
kind=unstacked)
You can look for users that have been invited, but have not yet redeemed their invite. Guest invites never expire, so if a user hasn’t accepted after a couple of months it may be worth removing the invite until a time they genuinely require it. In this query we exclude invites sent in the last month, as those people may have simply not got around to redeeming their invite yet.
//Lists guests who have been invited but not yet redeemed their invites. Excludes newly invited guests (last 30 days).
let timerange=180d;
let timeframe=30d;
AuditLogs
| where TimeGenerated between (ago(timerange) .. ago(timeframe))
| where OperationName == "Invite external user"
| extend GuestUPN = tolower(tostring(TargetResources[0].userPrincipalName))
| project TimeGenerated, GuestUPN
| join kind=leftanti (
AuditLogs
| where TimeGenerated > ago (timerange)
| where OperationName == "Redeem external user invite"
| where CorrelationId <> "00000000-0000-0000-0000-000000000000"
| extend d = tolower(tostring(TargetResources[0].displayName))
| parse d with * "upn: " GuestUPN "," *
| project TimeGenerated, GuestUPN)
on GuestUPN
| distinct GuestUPN
For those users that have accepted and are actively accessing applications, we can see what they are accessing just like a regular user. You could break down all your apps and have a look at the split between guests and members for each application.
//Creates a list of your applications and summarizes successful signins by members vs guests
let timerange=30d;
SigninLogs
| where TimeGenerated > ago(timerange)
| project TimeGenerated, UserType, ResultType, AppDisplayName
| where ResultType == 0
| summarize
MemberSignins=countif(UserType == "Member"),
GuestSignins=countif(UserType == "Guest")
by AppDisplayName
| sort by AppDisplayName
You can quickly see which users haven’t signed in over the last month, having signed in successfully in the preceding 6 months.
let timerange=180d;
let timeframe=30d;
SigninLogs
| where TimeGenerated > ago(timerange)
| where UserType == "Guest" or UserPrincipalName contains "#ext#"
| where ResultType == 0
| summarize arg_max(TimeGenerated, *) by UserPrincipalName
| join kind = leftanti
(
SigninLogs
| where TimeGenerated > ago(timeframe)
| where UserType == "Guest" or UserPrincipalName contains "#ext#"
| where ResultType == 0
| summarize arg_max(TimeGenerated, *) by UserPrincipalName
)
on UserPrincipalName
| project UserPrincipalName
Or you could even summarize all your guests (who have signed in at least once) into the month they last accessed your tenant. You could then bulk disable/delete anything over 3 months or whatever your lifecycle policy is.
//Month by month breakdown of when your Azure AD guests last signed in
SigninLogs
| where TimeGenerated > ago (360d)
| where UserType == "Guest" or UserPrincipalName contains "#ext#"
| where ResultType == 0
| summarize arg_max(TimeGenerated, *) by UserPrincipalName
| project TimeGenerated, UserPrincipalName
| summarize InactiveUsers=make_set(UserPrincipalName) by startofmonth(TimeGenerated)
You could look at guests accounts that are trying to access your applications but being denied because they aren’t assigned a role, this could potentially be some reconnaissance occurring in your environment.
SigninLogs
| where UserType == "Guest"
| where ResultType == "50105"
| project TimeGenerated, UserPrincipalName, AppDisplayName, IPAddress, Location, UserAgent
We can leverage the IdentityInfo table to find any guests that have been assigned Azure AD roles. If your security controls for guests are weaker than your member accounts this is something you definitely want to avoid.
IdentityInfo
| where TimeGenerated > ago(21d)
| summarize arg_max(TimeGenerated, *) by AccountUPN
| where UserType == "Guest"
| where AssignedRoles != "[]"
| where isnotempty(AssignedRoles)
| project AccountUPN, AssignedRoles, AccountObjectId
We can also use our IdentityInfo table again to grab a list of all our guests, then join to our OfficeActivity table to summarize download activities by each of your guests.
//Summarize the total count and the list of files downloaded by guests in your Office 365 tenant
let timeframe=30d;
IdentityInfo
| where TimeGenerated > ago(21d)
| where UserType == "Guest"
| summarize arg_max(TimeGenerated, *) by AccountUPN
| project UserId=tolower(AccountUPN)
| join kind=inner (
OfficeActivity
| where TimeGenerated > ago(timeframe)
| where Operation in ("FileSyncDownloadedFull", "FileDownloaded")
)
on UserId
| summarize DownloadCount=count(), DownloadList=make_set(OfficeObjectId) by UserId
If you wanted to summarize which domains are downloading the most data from Office 365 then you can slightly alter the above query (thanks to Alex Verboon for this suggestion).
//Summarize the total count of files downloaded by each guest domain in your tenant
let timeframe=30d;
IdentityInfo
| where TimeGenerated > ago(21d)
| where UserType == "Guest"
| summarize arg_max(TimeGenerated, *) by AccountUPN, MailAddress
| project UserId=tolower(AccountUPN), MailAddress
| join kind=inner (
OfficeActivity
| where TimeGenerated > ago(timeframe)
| where Operation in ("FileSyncDownloadedFull", "FileDownloaded")
)
on UserId
| extend username = tostring(split(UserId,"#")[0])
| parse MailAddress with * "@" userdomain
| summarize count() by userdomain
You can find guests who were added to a Team then instantly started downloading data from your Office 365 tenant.
// Finds guest accounts who were added to a Team and then downloaded documents straight away.
// startime = data to look back on, timeframe = looks for downloads for this period after being added to the Team
let starttime = 7d;
let timeframe = 2h;
let operations = dynamic(["FileSyncDownloadedFull", "FileDownloaded"]);
OfficeActivity
| where TimeGenerated > ago(starttime)
| where OfficeWorkload == "MicrosoftTeams"
| where Operation == "MemberAdded"
| extend UserAdded = tostring(parse_json(Members)[0].UPN)
| where UserAdded contains ("#EXT#")
| project TimeAdded=TimeGenerated, UserId=tolower(UserAdded)
| join kind=inner
(
OfficeActivity
| where Operation in (['operations'])
)
on UserId
| project DownloadTime=TimeGenerated, TimeAdded, SourceFileName, UserId
| where (DownloadTime - TimeAdded) between (0min .. timeframe)
I think the key takeaway is that basically all your threat hunting queries you write for your standard accounts are most likely relevant to guests, and in some cases more relevant. While having guests in your tenant grants us some control and visibility, it is still an account not entirely under your management. The accounts could have poor passwords, or be shared amongst people, or if coming from another Azure AD tenancy could have poor lifecycle management, i.e they could have left the other company but their account is still active.
As always, prevention is better than detection, and depending on your licensing tier there are some great tools available to govern these accounts.
You can configure guest access restrictions in the Azure Active Directory portal. Keep in mind when configuring these options the flow on effect to other apps, such as Teams. In that same portal you can configure who is allowed to send guest invites, I would particularly recommend you disallow guests inviting other guests. You can also restrict or allow specific domains that invites can be sent to.
On your enterprise applications, make sure you have assignment required set to Yes
This is crucial in my opinion, because it allows Azure AD to be the first ‘gate’ to accessing your applications. The access control in your various applications is going to vary wildly. Some may need an account setup on the application itself to allow people in, some may auto create an account on first sign on, some may have no access control at all and when it sees a sign in from Azure AD it allows the person in. If this is set to no and your applications don’t perform their own access control or RBAC then there is a good chance your guests will be allowed in, as they come through as authenticated from Azure AD much like a member account.
If you are an Azure AD P2 customer, then you have access to Access Reviews, which is an already great and constantly improving offering that lets you automate a lot of the lifecycle of your accounts, including guests. You can also look at leveraging Entitlement Management which can facilitate granting guests the access they require and nothing more.
If you have Azure AD P1 or P2, use Azure AD Conditional Access, you can target policies specifically at guest accounts from within the console.
You can enforce MFA on your guest accounts like you would all other users – if you enforce MFA on an application for guests, the first time they access it they will be redirected to the MFA registration page. You can also explicitly block guests from particular applications using conditional access.
Also unrelated, I recently kicked off a #365daysofkql challenge on my twitter, where I share a query a day for a year, we are nearly one month in so if you want to follow feel free.
Azure Active Directory doesn’t really need any introduction, it is the core of identity within Microsoft 365, used by Azure RBAC and used by millions as an identity provider. The thing about Azure Active Directory is that it isn’t much like Active Directory at all, apart from name they have little in common under the hood. There is no LDAP, no Kerberos, no OU’s. Instead we get SAML, OIDC/OAuth and Microsoft Graph. It has its own unique threats, logging and attack vectors. There are a massive amount of great articles about attacking Azure AD, such as:
The focus of this blog is looking at it from the other side, looking for how we can detect and defend against these activities.
Defending Reconnaissance
Protection against directory reconnaissance in Azure Active Directory can be quite difficult. Any user in your tenant comes with some level of privilege, mostly to be able to ‘look around’ at other objects. You can restrict access to the Azure AD administration portal to users who don’t hold a privileged role under the ‘User settings’ tab in Azure Active Directory and you can configure guest permissions if you use external identities, it won’t stop people using other techniques but it still valuable to harden that portal.
With on-premise Active Directory we get logging on services like LDAP or DNS, and we have products like Defender for Id that can trigger alerts for us – on premise Active Directory has a very strong logging capability. For Azure Active Directory however, we don’t have access to equivalent data unfortunately, we will get sign-in activity of course – so if a user connects to Azure AD PowerShell, that can be tracked. What we can’t see though is the output for any read/get operations. So once connected to PowerShell if a user runs a Get-AzureADUser command, we have no visibility on that. Once a user starts to make changes, such as changing group memberships or deleting users, then we receive log events.
Tools like Azure AD Identity Protection are helpful, but they are sign-in driven and designed to protect users from account compromise. Azure AD Identity Protection won’t detect privilege escalation in Azure AD like Defender for Id for on premise Active Directory can.
So, while that makes things difficult, looking for users signing onto Azure management portals and interfaces is a good place to start –
SigninLogs
| where AppDisplayName in ("Azure Active Directory PowerShell","Microsoft Azure PowerShell","Graph Explorer", "ACOM Azure Website")
| project TimeGenerated, UserPrincipalName, AppDisplayName, Location, IPAddress, UserAgent
These applications have legitimate use though and we don’t want alert fatigue, so to add some more logic to our query, we can look back on the last 90 days (or whatever time frame suits you), then detect users accessing these applications for the first time. This could be a sign of a compromised account being used for reconnaissance.
let timeframe = startofday(ago(60d));
let applications = dynamic(["Azure Active Directory PowerShell", "Microsoft Azure PowerShell", "Graph Explorer", "ACOM Azure Website"]);
SigninLogs
| where TimeGenerated > timeframe and TimeGenerated < startofday(now())
| where AppDisplayName in (applications)
| project UserPrincipalName, AppDisplayName
| join kind=rightanti
(
SigninLogs
| where TimeGenerated > startofday(now())
| where AppDisplayName in (applications)
)
on UserPrincipalName, AppDisplayName
| where ResultType == 0
| project TimeGenerated, UserPrincipalName, ResultType, AppDisplayName, IPAddress, Location, UserAgent
Defending Excessive User Permission
This one is fairly straight forward, but often the simplest things are hardest to get right. Your IT staff, or yourself, will need to manage Azure AD and that’s fine of course, but we need to make sure that roles are fit for purpose. Azure AD has a list of pre-canned and well documented roles, and you can build your own if required. Make sure that roles are being assigned that are appropriate to the job – you don’t need to be a Global Administrator to complete user administration tasks, there are better suited roles. We can detect the assignment of roles to users, if you use Azure AD PIM we can also exclude activations from our query –
AuditLogs
| where Identity <> "MS-PIM"
| where OperationName == "Add member to role"
| extend Target = tostring(TargetResources[0].userPrincipalName)
| extend RoleAdded = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[1].newValue)))
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend ActorIPAddress = tostring(parse_json(tostring(InitiatedBy.user)).ipAddress)
| project TimeGenerated, OperationName, Target, RoleAdded, Actor, ActorIPAddress
If you have a lot of users being moved in and out of roles you can reduce the query down to a selected set of privileged roles if required –
let roles=dynamic(["Global Admininistrator","SharePoint Administrator","Exchange Administrator"]);
AuditLogs
| where OperationName == "Add member to role"
| where Identity <> "MS-PIM"
| extend Target = tostring(TargetResources[0].userPrincipalName)
| extend RoleAdded = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[1].newValue)))
| where RoleAdded in (roles)
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend ActorIPAddress = tostring(parse_json(tostring(InitiatedBy.user)).ipAddress)
| project TimeGenerated, OperationName, Target, RoleAdded, Actor, ActorIPAddress
And if you use Azure AD PIM you can be alerted when users are assigned roles outside of the PIM platform (which you can do via Azure AD PowerShell as an example) –
AuditLogs
| where OperationName startswith "Add member to role outside of PIM"
| extend RoleAdded = tostring(TargetResources[0].displayName)
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend ActorIPAddress = tostring(parse_json(tostring(InitiatedBy.user)).ipAddress)
| extend TargetAADUserId = tostring(TargetResources[2].id)
| project TimeGenerated, OperationName, TargetAADUserId, RoleAdded, Actor
Defending Shared Identity
Unless you are a cloud native company with no on premise Active Directory footprint then you will be syncing user accounts, group objects and devices between on premise and Azure AD. Whether you sync all objects, or a subset of them will depend on your particular environment, but identity is potentially the link between AD and Azure AD. If you use accounts from on premise Active Directory to also manage Azure Active Directory, then the identity security of those accounts are crucial. Microsoft recommend you use cloud only accounts to manage Azure AD, but that may not be practical in your environment, or it’s something you are working toward.
Remember that Azure Active Directory and Active Directory essentially have no knowledge of the privilege an account has on the other system (apart from group membership more broadly). Active Directory doesn’t know that bobsmith@yourcompany.com is a Global Administrator, and Azure Active Directory doesn’t know that the same account has full control over particular OUs as an example. We can visualize this fairly simply.
In isolation each system has its own built in protections, a regular user can’t reset the password of a Domain Admin on premise and in Azure AD a User Administrator can’t reset the password of a Global Administrator. The issue is when we cross that boundary and where there is a link in identity, there is potential for abuse and escalation.
For arguments sake maybe our service desk staff have the privilege to reset the password on a Global Administrator account in Azure AD – because of inherit permissions in AD. It may be easier for an attacker to target a service desk account because they have weaker controls or may be more vulnerable to social engineering – “hey could you reset the password on bobsmith@yourcompany.com for me?”. In on premise AD that account may appear to be quite low privilege.
We can leverage the IdentityInfo table driven by Azure Sentinel UEBA to track down users who have privileged roles, then join that back to on premise SecurityEvents for password reset activity. Then filter out when a privileged Azure AD user has reset their own on premise password – we want events where someone has reset another persons privileged Azure AD account.
let timeframe=1d;
IdentityInfo
| where TimeGenerated > ago(21d)
| where isnotempty(AssignedRoles)
| where AssignedRoles != "[]"
| summarize arg_max(TimeGenerated, *) by AccountUPN
| project AccountUPN, AccountName, AccountSID
| join kind=inner (
SecurityEvent
| where TimeGenerated > ago(timeframe)
| where EventID == "4724"
| project
TimeGenerated,
Activity,
SubjectAccount,
TargetAccount,
TargetSid,
SubjectUserSid
)
on $left.AccountSID == $right.TargetSid
| where SubjectUserSid != TargetSid
| project PasswordResetTime=TimeGenerated, Activity, ActorAccountName=SubjectAccount, TargetAccountUPN=AccountUPN,TargetAccountName=TargetAccount
The reverse can be true too, you could have users with Azure AD privilege, but no or reduced access to on premise Active Directory. When an Azure AD admin resets a password it is logged as a ‘Reset password (by admin)’ action in Azure Sentinel, we can retrieve the actor, the target and the outcome –
An attacker could go further and use a service principal to leverage Microsoft Graph to initiate a password reset in Azure AD and have it written back to on-premise. This activity is shown in the AuditLogs table –
AuditLogs
| where OperationName == "POST UserAuthMethod.ResetPasswordOnPasswordMethods"
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| project TimeGenerated, OperationName, Actor, CorrelationId
| join kind=inner
(AuditLogs
| where OperationName == "Reset password (by admin)"
| extend Target = tostring(TargetResources[0].userPrincipalName)
| where Result == "success"
)
on CorrelationId
| project GraphPostTime=TimeGenerated, PasswordResetTime=TimeGenerated1, Actor, Target
Not only can on premise users have privileged in Azure AD, but on premise groups may hold privilege in Azure AD. When groups are synced from on premise to Azure AD, they don’t retain any of the security information from on premise. So you may have a group called ‘ad.security.appowners’, and that group can be managed by any number of people. If that group is then given any kind of privilege in Azure AD then the members of it inherit that privilege too. If you do have any groups in your environment that fit that pattern they will be unique to your environment, but you can detect changes to groups in Azure Sentinel –
SecurityEvent
| extend Actor = Account
| extend Target = MemberName
| extend Group = TargetAccount
| where EventID in (4728,4729,4732,4733,4756,4757) and Group == "DOMAIN\\ad.security.appowners"
| project TimeGenerated, Activity, Actor, Target, Group
If you have a list of groups you want to monitor, then it’s worth adding them into a watchlist and then querying against that, then you can keep the watchlist current and your query will continue to be up to date.
let watchlist = (_GetWatchlist('PrivilegedADGroups') | project TargetAccount);
SecurityEvent
extend Target = MemberName
| extend Group = TargetAccount
| where EventID in (4728,4729,4732,4733,4756,4757) and TargetAccount in (watchlist)
| project TimeGenerated, Activity, Actor, Target, Group
If you have these shared identities and groups, what the groups are named will be very specific to you, but you should look to harden the security on premise, monitor them or preferably de-couple the link between AD and Azure AD entirely.
Defending Service Principal Abuse
In Azure AD, we can register applications, authenticate against them (using secrets or certificates) and they can provide further access into Azure AD or any other resources in your tenant – for each application created a corresponding service principal is created too. We can add either delegated or application access to app (such as mail.readwrite.all from the MS Graph) and we can assign roles (such as Global Administrator) to the service principal. Anyone who then authenticates to the app would have the attached privilege.
Specterops posted a great article here (definitely worth reading before continuing) highlighting the privilege escalation path through service principals. The article outlines some potential weak points spots in Azure AD –
Application admins being able to assign new secrets (passwords) to existing service principals.
High privilege roles being assigned to service principals.
And we will add some additional threats that you may see
Admins consenting to excessive permissions.
Redirect URI tampering.
From the article we learnt that the Application Administrator role has the ability to add credentials (secrets or certificates) to any existing application in Azure AD. If you have a service principal that has the Global Administrator role or privilege to the MS Graph, then an Application Administrator can generate a new secret for that app and effectively be a Global Administrator and obtain that privilege.
We can view secrets generated on an app in the AuditLogs table –
AuditLogs
| where OperationName contains "Update application – Certificates and secrets management"
| extend AppId = tostring(AdditionalDetails[1].value)
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend AppDisplayName = tostring(TargetResources[0].displayName)
| project TimeGenerated, OperationName, AppDisplayName, AppId, Actor
We can also detect when permissions change in Azure AD applications, much like on premise service accounts, privilege has a tendency to creep upward over time. We can detect application permission additions with –
AuditLogs
| where OperationName == "Add app role assignment to service principal"
| extend AppPermissionsAdded = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[1].newValue)))
| extend AppId = tostring(TargetResources[1].id)
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend ActorIPAddress = tostring(parse_json(tostring(InitiatedBy.user)).ipAddress)
| project TimeGenerated, OperationName, AppId, AppPermissionsAdded,Actor, ActorIPAddress
Some permissions are of a high enough level that Azure AD requires a global administrator to consent to them, essentially by hitting an approve button. This is definitely an action you want to audit and investigate, once a global administrator hits the consent button, the privilege has been granted. You can investigate consent actions, including the permissions that have been granted –
From the Specterops article, one of the red flags we mentioned was Azure AD roles being assigned to service principals, we often worry about excessive privilege for users, but forget about apps & service principals. We can detect a role being added to service principals –
AuditLogs
| where OperationName == "Add member to role"
| where TargetResources[0].type == "ServicePrincipal"
| extend ServicePrincipalObjectID = tostring(TargetResources[0].id)
| extend AppDisplayName = tostring(TargetResources[0].displayName)
| extend Actor = tostring(parse_json(tostring(InitiatedBy.user)).userPrincipalName)
| extend RoleAdded = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[1].newValue)))
| project TimeGenerated, Actor, RoleAdded, ServicePrincipalObjectID, AppDisplayName
For Azure AD applications you may also have configured a redirect URI, this is the location that Azure AD will redirect the user & token after authentication. So if you have an application that is used to sign people in you will be likely sending the user & token to an address like https://app.mycompany.com/auth. Applications in Azure AD can have multiple URI’s assigned, so if an attacker was to then add https://maliciouswebserver.com/auth as a target then the data would be posted there too. We can detect changes in redirect URI’s –
AuditLogs
| where OperationName contains "Update application"
| where Result == "success"
| extend UpdatedProperty = tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[0].displayName)
| where UpdatedProperty == "AppAddress"
| extend NewRedirectURI = tostring(parse_json(tostring(parse_json(tostring(TargetResources[0].modifiedProperties))[0].newValue))[0].Address)
| where isnotempty( NewRedirectURI)
| project TimeGenerated, OperationName, UpdatedProperty, NewRedirectURI
Remember that Azure AD service principals are identities too, so that we can use tooling like Azure AD Conditional Access to control where they can logon from. Have an application registered in Azure AD that provides authentication for an API that is only used from a particular location? You can enforce that with conditional access much like you would user sign-ins.
Service principal sign-ins are held in the AADServicePrincipalSignInLogs table in Azure Sentinel, the structure is similar to regular sign ins so you can look in trends in the data much like interactive sign-ins and start to detect anything out of the ordinary.
Service principals can generate errors on logons too, an error 7000215 in the AADServicePrincipalSignInLogs table is an invalid secret, or the service principal equivalent of a wrong password.
While the focus on this blog was detection, which is a valuable tool, prevention is even better.
Prevention can be straight forward, or extremely complex and what you can achieve in your environment is unique to you, but there are definitely some recommendations worth following –
Limit access to Azure management portals and interfaces to those that need it via Azure AD Conditional Access. For those applications that you can’t apply policy to, alert for suspicious connections.
Provide access to Azure AD roles following least privilege principals – don’t hand out Global Administrator for tasks that User Administrator could cover.
Use Azure AD PIM if licensed for it and alert on users being assigned to roles outside of PIM.
Limit access to roles that can manage Azure AD Applications – if a team wants to manage their applications, they can be made owners on their specific apps, not across them all.
Alert on privileged changes to Azure AD apps – new secrets, new redirect URI’s, added permissions or admin consent.
Treat access to the Microsoft Graph and Azure AD as you would on premise AD. If an application or team request directory.readwrite.all or to be a Global Admin then push back and ask what actions are they trying to perform – there is likely a much lower level of privilege that would work.
Don’t allow long lived secrets on Azure AD apps, this is the equivalent of ‘password never expires’.
If you use hybrid identity be aware of users, groups or services that can leverage privilege in Azure AD to make changes in on premise AD, or vice versa.
Look for anomalous activity in service principal sign in data.
The queries in this post aren’t exhaustive by any means, get to know the AuditLogs table, it is filled with plenty of operations you may find interesting – authentication methods being updated for users, PIM role setting changes, BitLocker keys being read. Line up the actions you see in the table to what is risky to you and what you want to stop. For those events, can we prevent them through policy? If not, how do we detect and respond quick enough.
For those who have a large on premise Active Directory environment, one of the challenges you may face is how to use Azure Sentinel to reset the passwords for on premise Active Directory accounts. There are plenty of ways to achieve this – you may have an integrated service environment that allows Logic Apps or Azure Functions to connect directly to on premise resources, like a domain controller. You can also use an Azure Automation account with a hybrid worker. There is a lesser known option though, if you have already deployed Azure AD self-service password reset (SSPR) then we can piggyback off of the password writeback that is enabled when you deployed it. When a user performs a password reset using SSPR the password is first changed in Azure AD, then written back to on premise AD to keep them in sync. If you want to use Azure Sentinel to automate password resets for compromised accounts, then we can leverage that existing connection.
To do this we are going to build a small logic app that uses two Microsoft Graph endpoints, which are
GET PasswordAuthenticationMethod – retrieves the id of the password we wish to reset based off the UserPrincipalName or Azure AD Object Id
Keep in mind that both these endpoints are currently in beta, so the usual disclaimers apply.
If we have a look at the documentation, you will notice that to retrieve the the id of the password we want to reset we can use delegated or application permissions.
However to reset a password, application permissions are not supported
So we will have to sign in as an actual user with sufficient privilege (take note of the roles required), and re-use that token for our automation. Not a huge deal, we will just use a different credential flow in our Logic App. Keep in mind this flow is only designed for programmatic access and shouldn’t be used interactively, because this will be run natively in Azure and won’t be end user facing it is still suitable.
So before you build your Logic App you will need an Azure AD app registration with delegated UserAuthenticationMethod.ReadWrite.All access and then an account (most likely a service account) with either the global admin, privileged authentication admin or authentication admin role assigned. You can store the credentials for these in an Azure Key Vault and use a managed identity on your Logic App to retrieve them securely.
Create a blank Logic App and use Azure Sentinel alert as the trigger, retrieve your account entities and then add your AAD User Id to a new variable, we will need it as we go.
Next we are going to retrieve the secrets for everything we will need to authenticate and authorize ourselves against. We will need to retrieve the ClientID, TenantID and Secret from our Azure AD app registration and our service account username and password.
There is a post here on how to retrieve the appropriate token using Logic Apps for delegated access, but to repeat it here, we will post to the Microsoft Graph.
Posting to the following URI with header Content-Type application/x-www-form-urlencoded –
In this example we will just pass the values straight from Azure Key Vault. Be sure to click the three dots and go to settings –
Then enable secure inputs, this will stop passwords being stored in the Logic App logs.
Now we just need to parse the response from Microsoft Graph so we can re-use our token, we will also then just build a string variable to format our token ready for use.
Then just create a string variable as above, appending Bearer before the token we parsed. Note there is a single space between Bearer and the token. Now we have our token, we can retrieve the id of the password of our user and then reset the password.
We will connect to the first API to retrieve the id of the password we want to change, using our bearer token as authorization, and passing in the variable of our AAD User Id who we want to reset.
Parse the response from our GET operation using the following schema –
Then we need to automate what our new password will be, an easy way of doing this is to generate a guid to use as a password – it is random, complex and should pass most password policies. Also if an account is compromised, this is just an automatic password reset, the user will then need to contact your help desk, or whoever is in responsible, confirm who they are and be issued with a password to use.
Then finally we take our AAD User Id from the Sentinel alert, the password id that we retrieved, and our new password and post it back to reset the password.
We use our bearer token again for authorization, content-type is application/json and the body is our new password – make sure to enable secure inputs again. You should be able to then run this playbook against any Azure Sentinel incident where you map your AAD User Id (or UserPrincipalName) as the entity. It will take about 30-40 seconds to reset the password and you should see a successful response.
You could add some further logic to email your team, or your service desk or whoever makes sense in your case to let them know that Azure Sentinel has reset a users password.
Just a couple of quick notes, this Logic App ties back to self service password reset, so any password resets you attempt will need to conform to any configuration you have done in your environment, such as –
Password complexity, if you have a domain policy requiring a certain complexity of password and your Logic App doesn’t meet it, you will get a PasswordPolicyError returned in the statusDetail field, much like a user doing an interactive self service password reset would.
The account you use to sync users to Azure AD will need access to reset passwords on any accounts you want to via Azure Sentinel, much like SSPR itself.